1faef74e7ddf364f30ed052c3a8b50ab919aa8a1,contents/4_Sarsa_lambda_maze/RL_brain.py,RL,choose_action,#RL#Any#,32
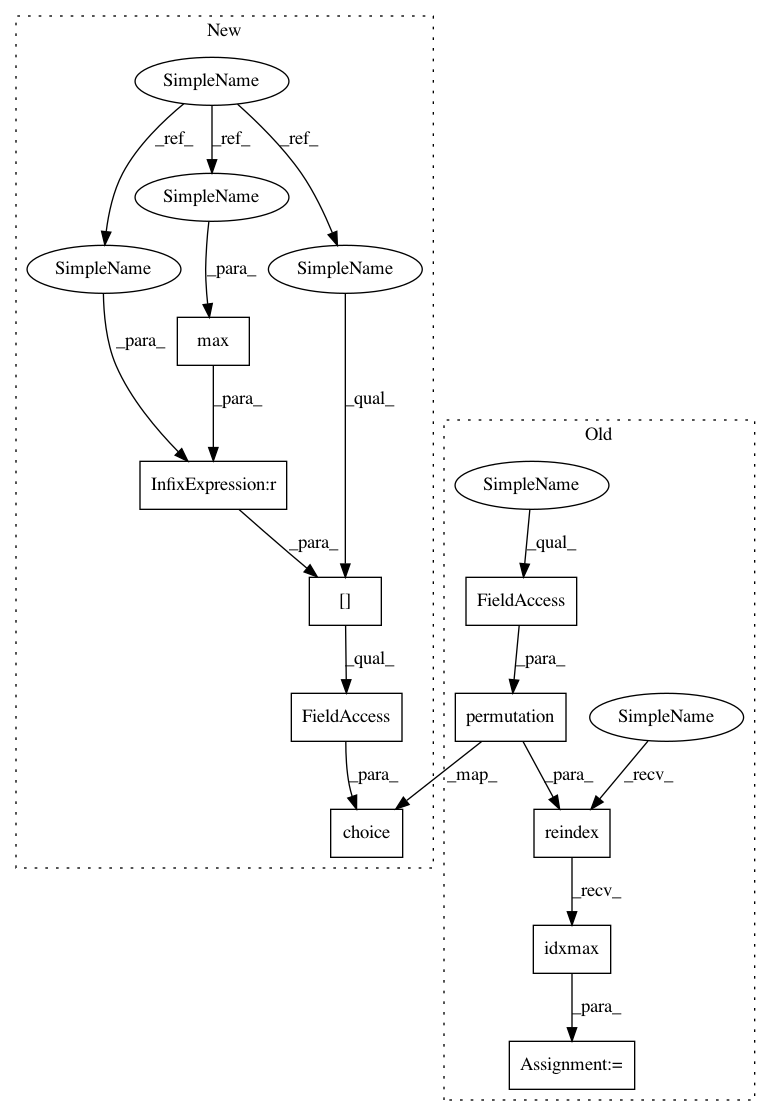
Before Change
if np.random.rand() < self.epsilon:
// choose best action
state_action = self.q_table.loc[observation, :]
state_action = state_action.reindex(np.random.permutation(state_action.index)) // some actions have same value
action = state_action.idxmax()
else:
// choose random action
action = np.random.choice(self.actions)
return actionAfter Change
// action selection
if np.random.rand() < self.epsilon:
// choose best action
state_action = self.q_table.loc[observation, :]
// some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
// choose random action
action = np.random.choice(self.actions)
return actionIn pattern: SUPERPATTERN
Frequency: 3
Non-data size: 10
Instances Project Name: MorvanZhou/Reinforcement-learning-with-tensorflow
Commit Name: 1faef74e7ddf364f30ed052c3a8b50ab919aa8a1
Time: 2018-09-02
Author: morvanzhou@gmail.com
File Name: contents/4_Sarsa_lambda_maze/RL_brain.py
Class Name: RL
Method Name: choose_action
Project Name: MorvanZhou/Reinforcement-learning-with-tensorflow
Commit Name: 1faef74e7ddf364f30ed052c3a8b50ab919aa8a1
Time: 2018-09-02
Author: morvanzhou@gmail.com
File Name: contents/2_Q_Learning_maze/RL_brain.py
Class Name: QLearningTable
Method Name: choose_action
Project Name: MorvanZhou/Reinforcement-learning-with-tensorflow
Commit Name: 1faef74e7ddf364f30ed052c3a8b50ab919aa8a1
Time: 2018-09-02
Author: morvanzhou@gmail.com
File Name: contents/3_Sarsa_maze/RL_brain.py
Class Name: RL
Method Name: choose_action