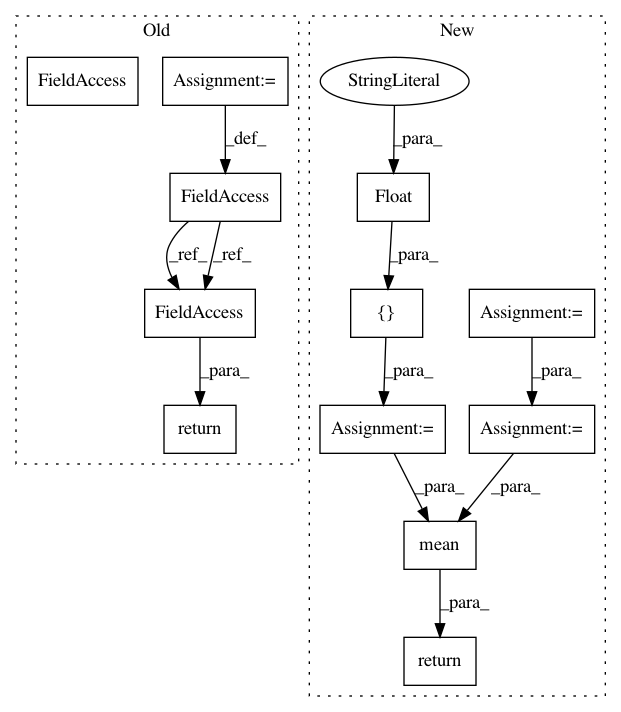
for _ in runner.step_epochs():
for cycle in range(self._steps_per_epoch):
runner.step_path = runner.obtain_trajectories(runner.step_itr)
last_return = self.train_once(runner.step_itr,
runner.step_path)
if (cycle == 0 and self.replay_buffer.n_transitions_stored >=
self._min_buffer_size):
runner.enable_logging = True
log_performance(runner.step_itr,
obtain_evaluation_samples(
self.policy, self._eval_env),
discount=self._discount)
runner.step_itr += 1
return last_return
def train_once(self, itr, trajectories):
Perform one step of policy optimization given one batch of samples.
After Change
if not self._eval_env:
self._eval_env = runner.get_env_copy()
last_returns = [float("nan")]
runner.enable_logging = False
qf_losses = []
for _ in runner.step_epochs():
for cycle in range(self._steps_per_epoch):
runner.step_path = runner.obtain_trajectories(runner.step_itr)
qf_losses.extend(
self.train_once(runner.step_itr, runner.step_path))
if (cycle == 0 and self.replay_buffer.n_transitions_stored >=
self._min_buffer_size):
runner.enable_logging = True
eval_samples = obtain_evaluation_samples(
self.policy, self._eval_env)last_returns = log_performance(runner.step_itr,
eval_samples,
discount=self._discount)
runner.step_itr += 1
tabular.record("DQN/QFLossMean", np.mean(qf_losses))
tabular.record("DQN/QFLossStd", np.std(qf_losses))
return np.mean(last_returns)
def train_once(self, itr, trajectories):
Perform one step of policy optimization given one batch of samples.