if len(csv_data_array) == 1:
output_dict[name] = np.asarray(csv_data_array[0])
else:
output_dict[name] = np.concatenate(csv_data_array,0)
else:
csv_data_array=[]
for n in range(0, self.window.n_samples):
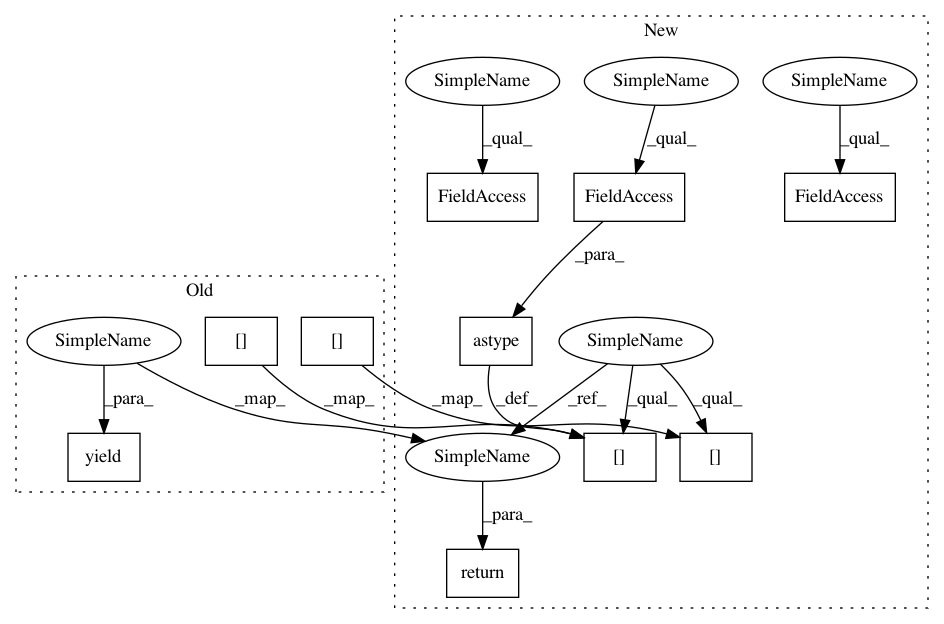
csv_data_array.append(csv_data_dict["sampler"])
if len(csv_data_array) == 1:
output_dict["sampler"] = np.asarray(csv_data_array[0])
else:
output_dict["sampler"] = np.concatenate(csv_data_array,0)
// _, label_dict, _ = self.csv_reader(subject_id=image_id)
// for name in self.csv_reader.task_param.keys():
//
// output_dict.update(label_dict)
for name in csv_data_dict.keys():
output_dict[name + "_location"] = output_dict["image_location"]
yield output_dict
// the output image shape should be
// [enqueue_batch_size, x, y, z, time, modality]
// where enqueue_batch_size = windows_per_image
After Change
// initialise output dict, placeholders as dictionary keys
// this dictionary will be used in
// enqueue operation in the form of: `feed_dict=output_dict`
output_dict = {}
// fill output dict with data
for name in list(data):
coordinates_key = LOCATION_FORMAT.format(name)
image_data_key = name
// fill the coordinates
location_array = coordinates[name]
output_dict[coordinates_key] = location_array
// fill output window array
image_array = []
for window_id in range(self.window.n_samples):
x_start, y_start, z_start, x_end, y_end, z_end = \
location_array[window_id, 1:]
try:
image_window = data[name][
x_start:x_end, y_start:y_end, z_start:z_end, ...]
image_array.append(image_window[np.newaxis, ...])
except ValueError:
tf.logging.fatal(
"dimensionality miss match in input volumes, "
"please specify spatial_window_size with a "
"3D tuple and make sure each element is "
"smaller than the image length in each dim. "
"Current coords %s", location_array[window_id])
raise
if len(image_array) > 1:
output_dict[image_data_key] = \
np.concatenate(image_array, axis=0)
else:
output_dict[image_data_key] = image_array[0]
// fill output dict with csv_data
if self.csv_reader is not None:
idx_dict = {}
list_keys = self.csv_reader.df_by_task.keys()
for k in list_keys:
if k == "sampler":
idx_dict[k] = idx
else:
for n in range(0, self.window.n_samples):
idx_dict[k] = 0
_, csv_data_dict,_ = self.csv_reader(idx=idx_dict,
subject_id=subject_id)
for name in csv_data_dict.keys():
if name != "sampler":
csv_data_array = []
for n in range(0, self.window.n_samples):
csv_data_array.append(csv_data_dict[name])
if len(csv_data_array) == 1:
output_dict[name] = np.asarray(csv_data_array[0],
dtype=np.float32)
else:
output_dict[name] = np.concatenate(
csv_data_array,0).astype(dtype=np.float32)
else:
csv_data_array=[]
for n in range(0, self.window.n_samples):
csv_data_array.append(csv_data_dict["sampler"])
if len(csv_data_array) == 1:
output_dict["sampler"] = np.asarray(csv_data_array[0],
dtype=np.float32)
else:
output_dict["sampler"] = np.concatenate(
csv_data_array,0).astype(np.float32)
// _, label_dict, _ = self.csv_reader(subject_id=image_id)
// for name in self.csv_reader.task_param.keys():
//
// output_dict.update(label_dict)
for name in csv_data_dict.keys():
output_dict[name + "_location"] = output_dict["image_location"]
return output_dict
// the output image shape should be
// [enqueue_batch_size, x, y, z, time, modality]
// where enqueue_batch_size = windows_per_image