b78d0685b201fa433507a4d4e1d0a0f70a0dc783,scripts/keras_benchmarks/models/lstm_text_generation_benchmark.py,LstmTextGenBenchmark,benchmarkLstmTextGen,#LstmTextGenBenchmark#Any#Any#,37
Before Change
path = get_file("nietzsche.txt", origin="https://s3.amazonaws.com/text-datasets/nietzsche.txt")
text = open(path).read().lower()
print("corpus length:", len(text))
chars = sorted(list(set(text)))
print("total chars:", len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))After Change
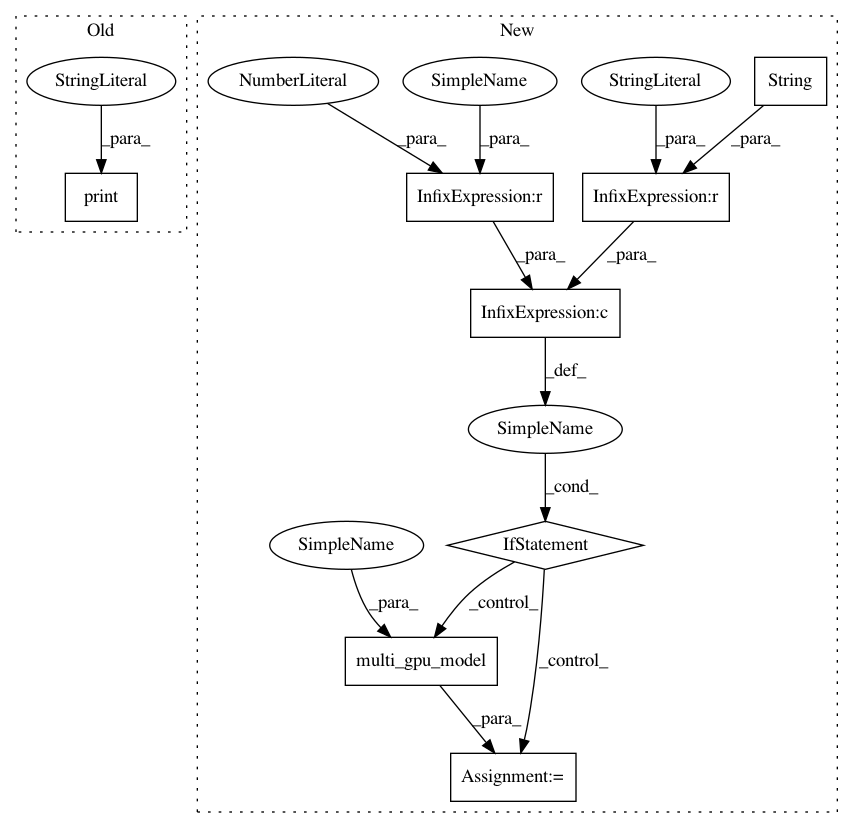
optimizer = RMSprop(lr=0.01)
if str(keras_backend) is "tensorflow" and gpu_count > 1:
model = multi_gpu_model(model, gpus=gpu_count)
model.compile(loss="categorical_crossentropy", optimizer=optimizer)
// train the model, output generated text after each iteration
start_time = time.time()In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 8
Instances Project Name: tensorflow/benchmarks
Commit Name: b78d0685b201fa433507a4d4e1d0a0f70a0dc783
Time: 2017-11-01
Author: anjalisridhar@google.com
File Name: scripts/keras_benchmarks/models/lstm_text_generation_benchmark.py
Class Name: LstmTextGenBenchmark
Method Name: benchmarkLstmTextGen
Project Name: tensorflow/benchmarks
Commit Name: b78d0685b201fa433507a4d4e1d0a0f70a0dc783
Time: 2017-11-01
Author: anjalisridhar@google.com
File Name: scripts/keras_benchmarks/models/lstm_text_generation_benchmark.py
Class Name: LstmTextGenBenchmark
Method Name: benchmarkLstmTextGen
Project Name: tensorflow/benchmarks
Commit Name: b78d0685b201fa433507a4d4e1d0a0f70a0dc783
Time: 2017-11-01
Author: anjalisridhar@google.com
File Name: scripts/keras_benchmarks/models/cifar10_cnn_benchmark.py
Class Name: Cifar10CnnBenchmark
Method Name: benchmarkCifar10Cnn
Project Name: tensorflow/benchmarks
Commit Name: b78d0685b201fa433507a4d4e1d0a0f70a0dc783
Time: 2017-11-01
Author: anjalisridhar@google.com
File Name: scripts/keras_benchmarks/models/mnist_irnn_benchmark.py
Class Name: MnistIrnnBenchmark
Method Name: benchmarkMnistIrnn