100f6cbd2f03bbd90d7b6a41cc81f711ed466491,petastorm/etl/metadata_index_run.py,,,#,23
Before Change
dataset_url = args.dataset_url
schema = locate(args.unischema_class)
if not schema:
raise ValueError("Schema {} could not be located".format(args.unischema_class))
// Open Spark Session
spark_session = SparkSession \
.builder \
.appName("Petastorm Metadata Index")
if args.master:
After Change
// Spark Context is available from the SparkSession
sc = spark.sparkContext
if args.unischema_class:
schema = locate(args.unischema_class)
else:
resolver = FilesystemResolver(dataset_url, sc._jsc.hadoopConfiguration())
dataset = pq.ParquetDataset(
resolver.parsed_dataset_url().path,
filesystem=resolver.filesystem(),
validate_schema=False)
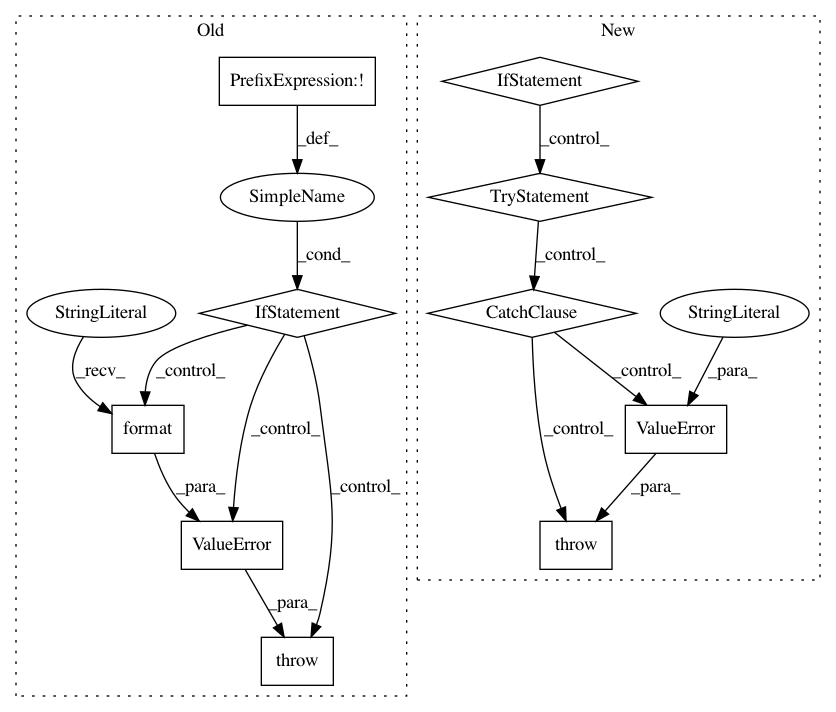
try:
schema = get_schema(dataset)
except ValueError:
raise ValueError("Schema could not be located in existing dataset."
" Please pass it into the job as --unischema_class")
with materialize_dataset(spark, dataset_url, schema):
// Inside the materialize dataset context we just need to write the metadata file as the schema will
// be written by the context manager.
// We use the java ParquetOutputCommitter to write the metadata file for the existing dataset
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 10
Instances
Project Name: uber/petastorm
Commit Name: 100f6cbd2f03bbd90d7b6a41cc81f711ed466491
Time: 2018-08-13
Author: robbieg@uber.com
File Name: petastorm/etl/metadata_index_run.py
Class Name:
Method Name:
Project Name: prody/ProDy
Commit Name: e93f4d4dcd70fc3eaf87779fc9f0b34f98e04ac8
Time: 2012-10-17
Author: lordnapi@gmail.com
File Name: lib/prody/utilities/pathtools.py
Class Name:
Method Name: gunzip
Project Name: GPflow/GPflow
Commit Name: baf110d82f60c51a5680e728cd3c5c6d3536117d
Time: 2017-09-24
Author: art.art.v@gmail.com
File Name: gpflow/params.py
Class Name: ParamList
Method Name: __init__