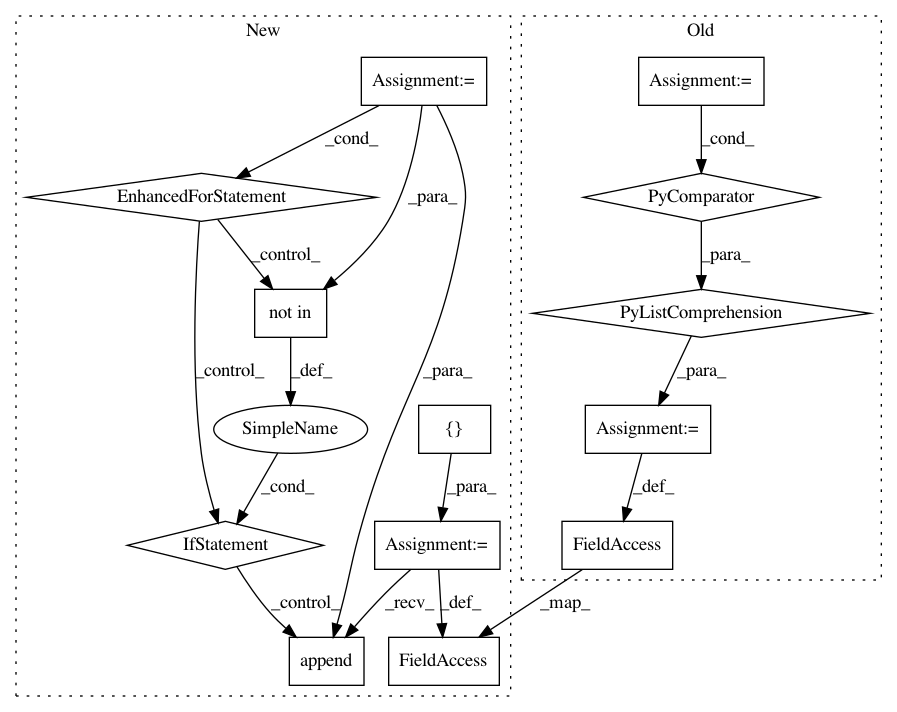
// Sometimes approximate features get computed in a previous filter frame
// and put in the current one dynamically,
// so there may be existing features here
features = [f for f in features if f.get_name()
not in frame.columns]
if not len(features):
progress_callback(len(features) / float(self.num_features))
return frame
// handle where
where = test_feature.where
if where is not None and not base_frame.empty:
base_frame = base_frame.loc[base_frame[where.get_name()]]
// when no child data, just add all the features to frame with nan
if base_frame.empty:
for f in features:
frame[f.get_name()] = np.nan
progress_callback(1 / float(self.num_features))
else:
relationship_path = test_feature.relationship_path
groupby_var = get_relationship_variable_id(relationship_path)
// if the use_previous property exists on this feature, include only the
// instances from the child entity included in that Timedelta
use_previous = test_feature.use_previous
if use_previous and not base_frame.empty:
// Filter by use_previous values
time_last = self.time_last
if use_previous.is_absolute():
time_first = time_last - use_previous
ti = child_entity.time_index
if ti is not None:
base_frame = base_frame[base_frame[ti] >= time_first]
else:
n = use_previous.value
def last_n(df):
return df.iloc[-n:]
base_frame = base_frame.groupby(groupby_var, observed=True, sort=False).apply(last_n)
to_agg = {}
agg_rename = {}
to_apply = set()
// apply multivariable and time-dependent features as we find them, and
// save aggregable features for later
for f in features:
if _can_agg(f):
variable_id = f.base_features[0].get_name()
if variable_id not in to_agg:
to_agg[variable_id] = []
func = f.get_function()
// for some reason, using the string count is significantly
// faster than any method a primitive can return
// https://stackoverflow.com/questions/55731149/use-a-function-instead-of-string-in-pandas-groupby-agg
if is_python_2() and func == pd.Series.count.__func__:
func = "count"
elif func == pd.Series.count:
func = "count"
funcname = func
if callable(func):
// if the same function is being applied to the same
// variable twice, wrap it in a partial to avoid
// duplicate functions
funcname = str(id(func))
if u"{}-{}".format(variable_id, funcname) in agg_rename:
func = partial(func)
funcname = str(id(func))
func.__name__ = funcname
to_agg[variable_id].append(func)
// this is used below to rename columns that pandas names for us
agg_rename[u"{}-{}".format(variable_id, funcname)] = f.get_name()
continue
to_apply.add(f)
// Apply the non-aggregable functions generate a new dataframe, and merge
// it with the existing one
if len(to_apply):
wrap = agg_wrapper(to_apply, self.time_last)
// groupby_var can be both the name of the index and a column,
// to silence pandas warning about ambiguity we explicitly pass
// the column (in actuality grouping by both index and group would
// work)
to_merge = base_frame.groupby(base_frame[groupby_var], observed=True, sort=False).apply(wrap)
frame = pd.merge(left=frame, right=to_merge,
left_index=True,
right_index=True, how="left")
progress_callback(len(to_apply) / float(self.num_features))
// Apply the aggregate functions to generate a new dataframe, and merge
// it with the existing one
if len(to_agg):
// groupby_var can be both the name of the index and a column,
// to silence pandas warning about ambiguity we explicitly pass
// the column (in actuality grouping by both index and group would
// work)
to_merge = base_frame.groupby(base_frame[groupby_var],
observed=True, sort=False).agg(to_agg)
// rename columns to the correct feature names
to_merge.columns = [agg_rename["-".join(x)] for x in to_merge.columns.ravel()]
to_merge = to_merge[list(agg_rename.values())]
// workaround for pandas bug where categories are in the wrong order
After Change
// Sometimes approximate features get computed in a previous filter frame
// and put in the current one dynamically,
// so there may be existing features here
fl = []for f in features:
for ind in f.get_feature_names():
if ind not in frame.columns:
fl.append(f)
break
features = fl
if not len(features):
progress_callback(len(features) / float(self.num_features))
return frame
// handle where
where = test_feature.where
if where is not None and not base_frame.empty:
base_frame = base_frame.loc[base_frame[where.get_name()]]
// when no child data, just add all the features to frame with nan
if base_frame.empty:
for f in features:
frame[f.get_name()] = np.nan
progress_callback(1 / float(self.num_features))
else:
relationship_path = test_feature.relationship_path
groupby_var = get_relationship_variable_id(relationship_path)
// if the use_previous property exists on this feature, include only the
// instances from the child entity included in that Timedelta
use_previous = test_feature.use_previous
if use_previous and not base_frame.empty:
// Filter by use_previous values
time_last = self.time_last
if use_previous.is_absolute():
time_first = time_last - use_previous
ti = child_entity.time_index
if ti is not None:
base_frame = base_frame[base_frame[ti] >= time_first]
else:
n = use_previous.value
def last_n(df):
return df.iloc[-n:]
base_frame = base_frame.groupby(groupby_var, observed=True, sort=False).apply(last_n)
to_agg = {}
agg_rename = {}
to_apply = set()
// apply multivariable and time-dependent features as we find them, and
// save aggregable features for later
for f in features:
if _can_agg(f):
variable_id = f.base_features[0].get_name()
if variable_id not in to_agg:
to_agg[variable_id] = []
func = f.get_function()
// for some reason, using the string count is significantly
// faster than any method a primitive can return
// https://stackoverflow.com/questions/55731149/use-a-function-instead-of-string-in-pandas-groupby-agg
if is_python_2() and func == pd.Series.count.__func__:
func = "count"
elif func == pd.Series.count:
func = "count"
funcname = func
if callable(func):
// if the same function is being applied to the same
// variable twice, wrap it in a partial to avoid
// duplicate functions
funcname = str(id(func))
if u"{}-{}".format(variable_id, funcname) in agg_rename:
func = partial(func)
funcname = str(id(func))
func.__name__ = funcname
to_agg[variable_id].append(func)
// this is used below to rename columns that pandas names for us
agg_rename[u"{}-{}".format(variable_id, funcname)] = f.get_name()
continue
to_apply.add(f)
// Apply the non-aggregable functions generate a new dataframe, and merge
// it with the existing one
if len(to_apply):
wrap = agg_wrapper(to_apply, self.time_last)
// groupby_var can be both the name of the index and a column,
// to silence pandas warning about ambiguity we explicitly pass
// the column (in actuality grouping by both index and group would
// work)
to_merge = base_frame.groupby(base_frame[groupby_var], observed=True, sort=False).apply(wrap)
frame = pd.merge(left=frame, right=to_merge,
left_index=True,
right_index=True, how="left")
progress_callback(len(to_apply) / float(self.num_features))
// Apply the aggregate functions to generate a new dataframe, and merge
// it with the existing one
if len(to_agg):
// groupby_var can be both the name of the index and a column,
// to silence pandas warning about ambiguity we explicitly pass
// the column (in actuality grouping by both index and group would
// work)
to_merge = base_frame.groupby(base_frame[groupby_var],
observed=True, sort=False).agg(to_agg)
// rename columns to the correct feature names
to_merge.columns = [agg_rename["-".join(x)] for x in to_merge.columns.ravel()]
to_merge = to_merge[list(agg_rename.values())]
// workaround for pandas bug where categories are in the wrong order