e4b6611cb73ef7658f028831be1aa6bd85ecbed0,src/garage/tf/policies/gaussian_mlp_policy.py,GaussianMLPPolicy,get_action,#GaussianMLPPolicy#Any#,168
Before Change
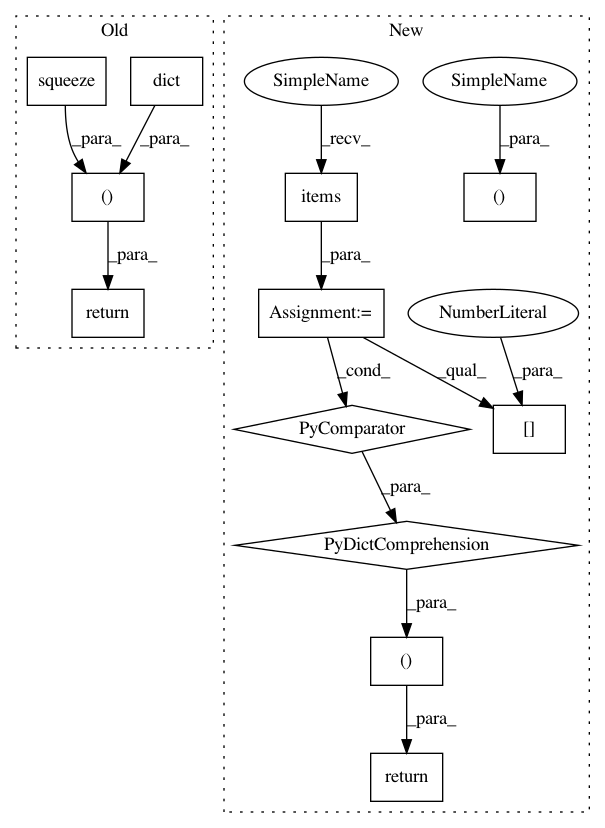
sample, mean, log_std = self._f_dist(np.expand_dims([observation], 1))
sample = self.action_space.unflatten(np.squeeze(sample, 1)[0])
mean = self.action_space.unflatten(np.squeeze(mean, 1)[0])
log_std = self.action_space.unflatten(np.squeeze(log_std, 1)[0])
return sample, dict(mean=mean, log_std=log_std)
def get_actions(self, observations):
Get multiple actions from this policy for the input observations.
After Change
distribution.
actions, agent_infos = self.get_actions([observation])
return actions[0], {k: v[0] for k, v in agent_infos.items()}
def get_actions(self, observations):
Get multiple actions from this policy for the input observations.
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 12
Instances
Project Name: rlworkgroup/garage
Commit Name: e4b6611cb73ef7658f028831be1aa6bd85ecbed0
Time: 2020-08-14
Author: 38871737+avnishn@users.noreply.github.com
File Name: src/garage/tf/policies/gaussian_mlp_policy.py
Class Name: GaussianMLPPolicy
Method Name: get_action
Project Name: rlworkgroup/garage
Commit Name: e4b6611cb73ef7658f028831be1aa6bd85ecbed0
Time: 2020-08-14
Author: 38871737+avnishn@users.noreply.github.com
File Name: src/garage/tf/policies/categorical_mlp_policy.py
Class Name: CategoricalMLPPolicy
Method Name: get_action
Project Name: rlworkgroup/garage
Commit Name: e4b6611cb73ef7658f028831be1aa6bd85ecbed0
Time: 2020-08-14
Author: 38871737+avnishn@users.noreply.github.com
File Name: src/garage/torch/policies/deterministic_mlp_policy.py
Class Name: DeterministicMLPPolicy
Method Name: get_action