True
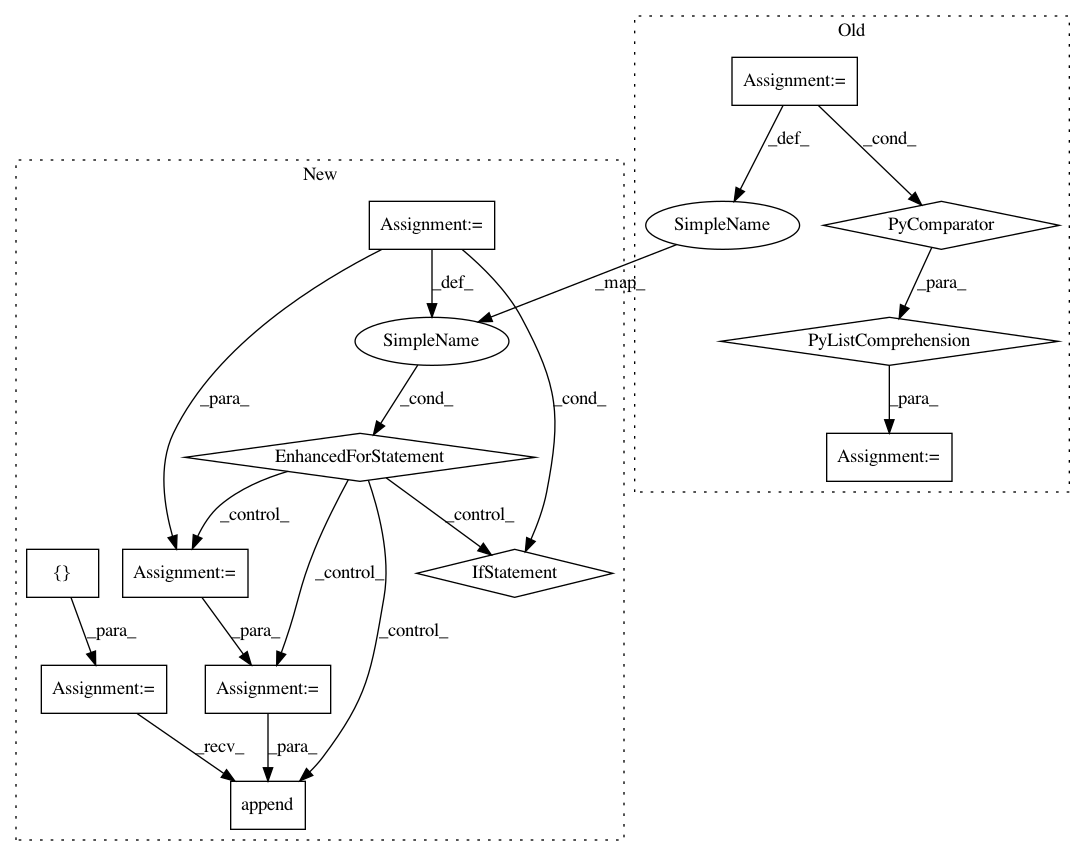
raw_tokens = self.tokenize(text)
// Convert converted quotes back to original double quotes
// Do this only if original text contains double quote(s)
if """ in text:
// Find double quotes and converted quotes
matched = [m.group() for m in re.finditer(r"[(``)(\"\")(")]+", text)]
// Replace converted quotes back to double quotes
tokens = [matched.pop(0) if tok in [""", "``", """"] else tok for tok in raw_tokens]
else:
tokens = raw_tokens
return align_tokens(tokens, text)