// If gradient clipping is used, calculate the huber loss
if config.clip_gradients > 0.0:
huber_loss = tf.where(tf.abs(delta) < config.clip_gradients, 0.5 * tf.square(delta), tf.abs(delta) - 0.5)
loss = tf.reduce_mean(huber_loss)
else:
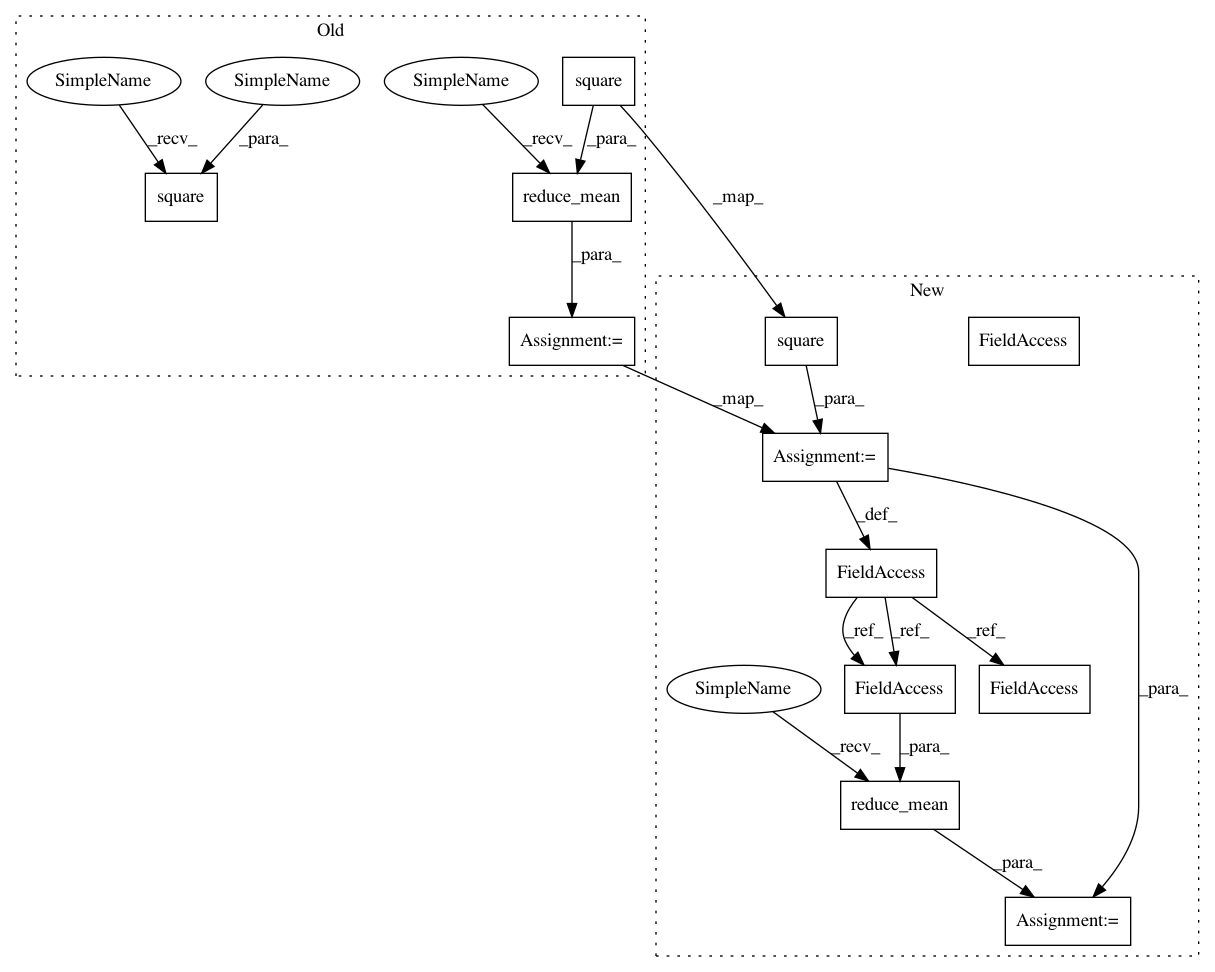
loss = tf.reduce_mean(tf.square(delta))
tf.losses.add_loss(loss)
// Update target network
with tf.name_scope("update_target"):
After Change
// Surrogate loss as the mean squared error between actual observed rewards and expected rewards
q_target = self.reward[:-1] + (1.0 - tf.cast(self.terminal[:-1], tf.float32)) * self.discount * target_value[action][1:]
delta = q_target - q_value
self.loss_per_instance = tf.square(delta)
// If gradient clipping is used, calculate the huber loss
if config.clip_gradients > 0.0:
huber_loss = tf.where(tf.abs(delta) < config.clip_gradients, 0.5 * self.loss_per_instance, tf.abs(delta) - 0.5)
loss = tf.reduce_mean(huber_loss)
else:
loss = tf.reduce_mean(self.loss_per_instance)
tf.losses.add_loss(loss)
// Update target network
with tf.name_scope("update_target"):