// embed fc and att feats
fc_feats = self.fc_embed(fc_feats)
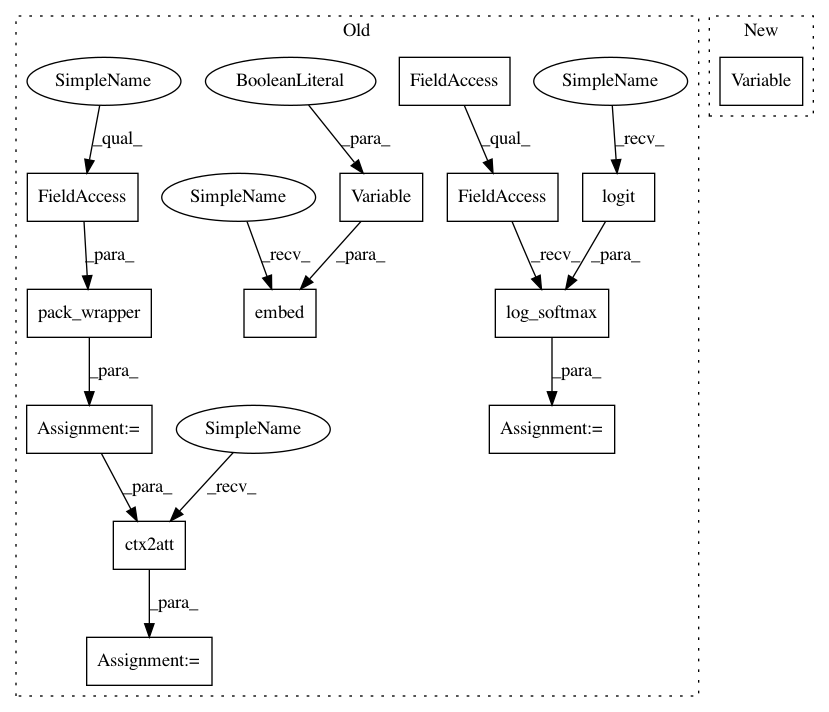
att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)
// Project the attention feats first to reduce memory and computation comsumptions.
p_att_feats = self.ctx2att(att_feats)
assert beam_size <= self.vocab_size + 1, "lets assume this for now, otherwise this corner case causes a few headaches down the road. can be dealt with in future if needed"
seq = torch.LongTensor(self.seq_length, batch_size).zero_()
seqLogprobs = torch.FloatTensor(self.seq_length, batch_size)
// lets process every image independently for now, for simplicity
self.done_beams = [[] for _ in range(batch_size)]
for k in range(batch_size):
state = self.init_hidden(beam_size)
tmp_fc_feats = fc_feats[k:k+1].expand(beam_size, fc_feats.size(1))
tmp_att_feats = att_feats[k:k+1].expand(*((beam_size,)+att_feats.size()[1:])).contiguous()
tmp_p_att_feats = p_att_feats[k:k+1].expand(*((beam_size,)+p_att_feats.size()[1:])).contiguous()
tmp_att_masks = att_masks[k:k+1].expand(*((beam_size,)+att_masks.size()[1:])).contiguous() if att_masks is not None else None
for t in range(1):
if t == 0: // input <bos>
it = fc_feats.data.new(beam_size).long().zero_()
xt = self.embed(Variable(it, requires_grad=False))
output, state = self.core(xt, tmp_fc_feats, tmp_att_feats, tmp_p_att_feats, state, tmp_att_masks)
logprobs = F.log_softmax(self.logit(output))
self.done_beams[k] = self.beam_search(state, logprobs, tmp_fc_feats, tmp_att_feats, tmp_p_att_feats, tmp_att_masks, opt=opt)
seq[:, k] = self.done_beams[k][0]["seq"] // the first beam has highest cumulative score
seqLogprobs[:, k] = self.done_beams[k][0]["logps"]
After Change
for t in range(1):
if t == 0: // input <bos>
it = Variable(fc_feats.data.new(beam_size).long().zero_())
logprobs, state = self.get_logprobs_state(it, tmp_fc_feats, tmp_att_feats, tmp_p_att_feats, tmp_att_masks, state)
self.done_beams[k] = self.beam_search(state, logprobs, tmp_fc_feats, tmp_att_feats, tmp_p_att_feats, tmp_att_masks, opt=opt)