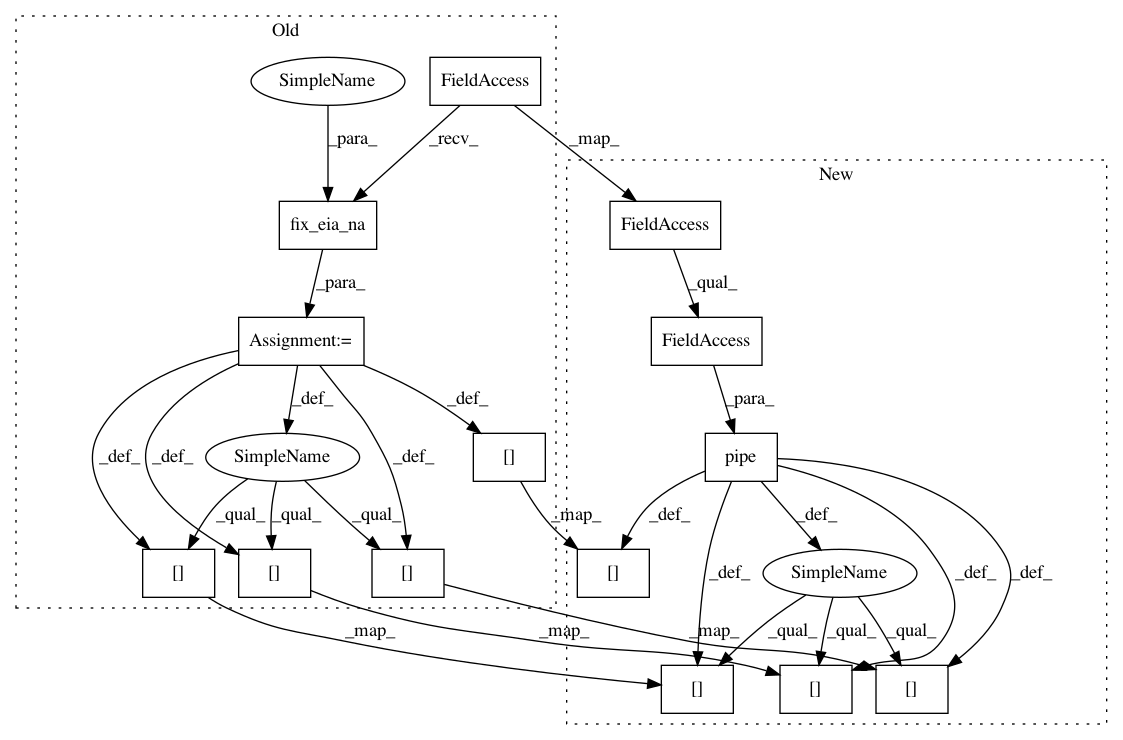
gens_df.dropna(subset=["generator_id", "plant_id_eia"], inplace=True)
// Replace empty strings, whitespace, and "." fields with real NA values
gens_df = pudl.helpers.fix_eia_na(gens_df)
// A subset of the columns have zero values, where NA is appropriate:
columns_to_fix = [
"planned_retirement_month",
"planned_retirement_year",
"planned_uprate_month",
"planned_uprate_year",
"other_modifications_month",
"other_modifications_year",
"planned_derate_month",
"planned_derate_year",
"planned_repower_month",
"planned_repower_year",
"planned_net_summer_capacity_derate_mw",
"planned_net_summer_capacity_uprate_mw",
"planned_net_winter_capacity_derate_mw",
"planned_net_winter_capacity_uprate_mw",
"planned_new_capacity_mw",
"nameplate_power_factor",
"minimum_load_mw",
"winter_capacity_mw",
"summer_capacity_mw"
]
for column in columns_to_fix:
gens_df[column] = gens_df[column].replace(
to_replace=[" ", 0], value=np.nan)
// A subset of the columns have "X" values, where other columns_to_fix
// have "N" values. Replacing these values with "N" will make for uniform
// values that can be converted to Boolean True and False pairs.
gens_df.duct_burners = \
gens_df.duct_burners.replace(to_replace="X", value="N")
gens_df.heat_bypass_recovery = \
gens_df.heat_bypass_recovery.replace(to_replace="X", value="N")
gens_df.syncronized_transmission_grid = \
gens_df.heat_bypass_recovery.replace(to_replace="X", value="N")
// A subset of the columns have "U" values, presumably for "Unknown," which
// must be set to None in order to convert the columns to datatype Boolean.
gens_df.multiple_fuels = \
gens_df.multiple_fuels.replace(to_replace="U", value=None)
gens_df.switch_oil_gas = \
gens_df.switch_oil_gas.replace(to_replace="U", value=None)
boolean_columns_to_fix = [
"duct_burners",
"multiple_fuels",
"deliver_power_transgrid",
"syncronized_transmission_grid",
"solid_fuel_gasification",
"pulverized_coal_tech",
"fluidized_bed_tech",
"subcritical_tech",
"supercritical_tech",
"ultrasupercritical_tech",
"carbon_capture",
"stoker_tech",
"other_combustion_tech",
"cofire_fuels",
"switch_oil_gas",
"heat_bypass_recovery",
"associated_combined_heat_power",
"planned_modifications",
"other_planned_modifications",
"uprate_derate_during_year",
"previously_canceled"
]
for column in boolean_columns_to_fix:
gens_df[column] = gens_df[column].fillna("False")
gens_df[column] = gens_df[column].replace(
to_replace=["Y", "N"], value=[True, False])
gens_df = (
gens_df.
pipe(pudl.helpers.month_year_to_date).
assign(fuel_type_code_pudl=lambda x: pudl.helpers.cleanstrings_series(
x["energy_source_code_1"], pc.fuel_type_eia860_simple_map)).
pipe(pudl.helpers.strip_lower,
columns=["rto_iso_lmp_node_id",
"rto_iso_location_wholesale_reporting_id"]).
astype({
"plant_id_eia": int,
"generator_id": str,
"utility_id_eia": int
}).
pipe(pudl.helpers.convert_to_date)
)
eia860_transformed_dfs["generators_eia860"] = gens_df
return eia860_transformed_dfs
After Change
ge_df["operational_status"] = "existing"
gr_df["operational_status"] = "retired"
gens_df = (
pd.concat([ge_df, gp_df, gr_df], sort=True)
.dropna(subset=["generator_id", "plant_id_eia"])
.pipe(pudl.helpers.fix_eia_na)
)
// A subset of the columns have zero values, where NA is appropriate:
columns_to_fix = [
"planned_retirement_month",
"planned_retirement_year",
"planned_uprate_month",
"planned_uprate_year",
"other_modifications_month",
"other_modifications_year",
"planned_derate_month",
"planned_derate_year",
"planned_repower_month",
"planned_repower_year",
"planned_net_summer_capacity_derate_mw",
"planned_net_summer_capacity_uprate_mw",
"planned_net_winter_capacity_derate_mw",
"planned_net_winter_capacity_uprate_mw",
"planned_new_capacity_mw",
"nameplate_power_factor",
"minimum_load_mw",
"winter_capacity_mw",
"summer_capacity_mw"
]
for column in columns_to_fix:
gens_df[column] = gens_df[column].replace(
to_replace=[" ", 0], value=np.nan)
// A subset of the columns have "X" values, where other columns_to_fix
// have "N" values. Replacing these values with "N" will make for uniform
// values that can be converted to Boolean True and False pairs.
gens_df.duct_burners = \
gens_df.duct_burners.replace(to_replace="X", value="N")
gens_df.heat_bypass_recovery = \
gens_df.heat_bypass_recovery.replace(to_replace="X", value="N")
gens_df.syncronized_transmission_grid = \
gens_df.heat_bypass_recovery.replace(to_replace="X", value="N")
// A subset of the columns have "U" values, presumably for "Unknown," which
// must be set to None in order to convert the columns to datatype Boolean.
gens_df.multiple_fuels = \
gens_df.multiple_fuels.replace(to_replace="U", value=None)
gens_df.switch_oil_gas = \
gens_df.switch_oil_gas.replace(to_replace="U", value=None)
boolean_columns_to_fix = [
"duct_burners",
"multiple_fuels",
"deliver_power_transgrid",
"syncronized_transmission_grid",
"solid_fuel_gasification",
"pulverized_coal_tech",
"fluidized_bed_tech",
"subcritical_tech",
"supercritical_tech",
"ultrasupercritical_tech",
"carbon_capture",
"stoker_tech",
"other_combustion_tech",
"cofire_fuels",
"switch_oil_gas",
"heat_bypass_recovery",
"associated_combined_heat_power",
"planned_modifications",
"other_planned_modifications",
"uprate_derate_during_year",
"previously_canceled"
]
for column in boolean_columns_to_fix:
gens_df[column] = gens_df[column].fillna("False")
gens_df[column] = gens_df[column].replace(
to_replace=["Y", "N"], value=[True, False])
gens_df = (
gens_df.
pipe(pudl.helpers.month_year_to_date).
assign(fuel_type_code_pudl=lambda x: pudl.helpers.cleanstrings_series(
x["energy_source_code_1"], pc.fuel_type_eia860_simple_map)).
pipe(pudl.helpers.strip_lower,
columns=["rto_iso_lmp_node_id",
"rto_iso_location_wholesale_reporting_id"]).
astype({
"plant_id_eia": int,
"generator_id": str,
"utility_id_eia": int
}).
pipe(pudl.helpers.convert_to_date)
)
eia860_transformed_dfs["generators_eia860"] = gens_df
return eia860_transformed_dfs