4a8379e34e122217400e7d2cfe4e7829db0c40c7,tensorlayer/files.py,,load_imdb_dataset,#Any#Any#Any#Any#Any#Any#Any#Any#Any#,440
Before Change
import numpy as np
from six.moves import urllib
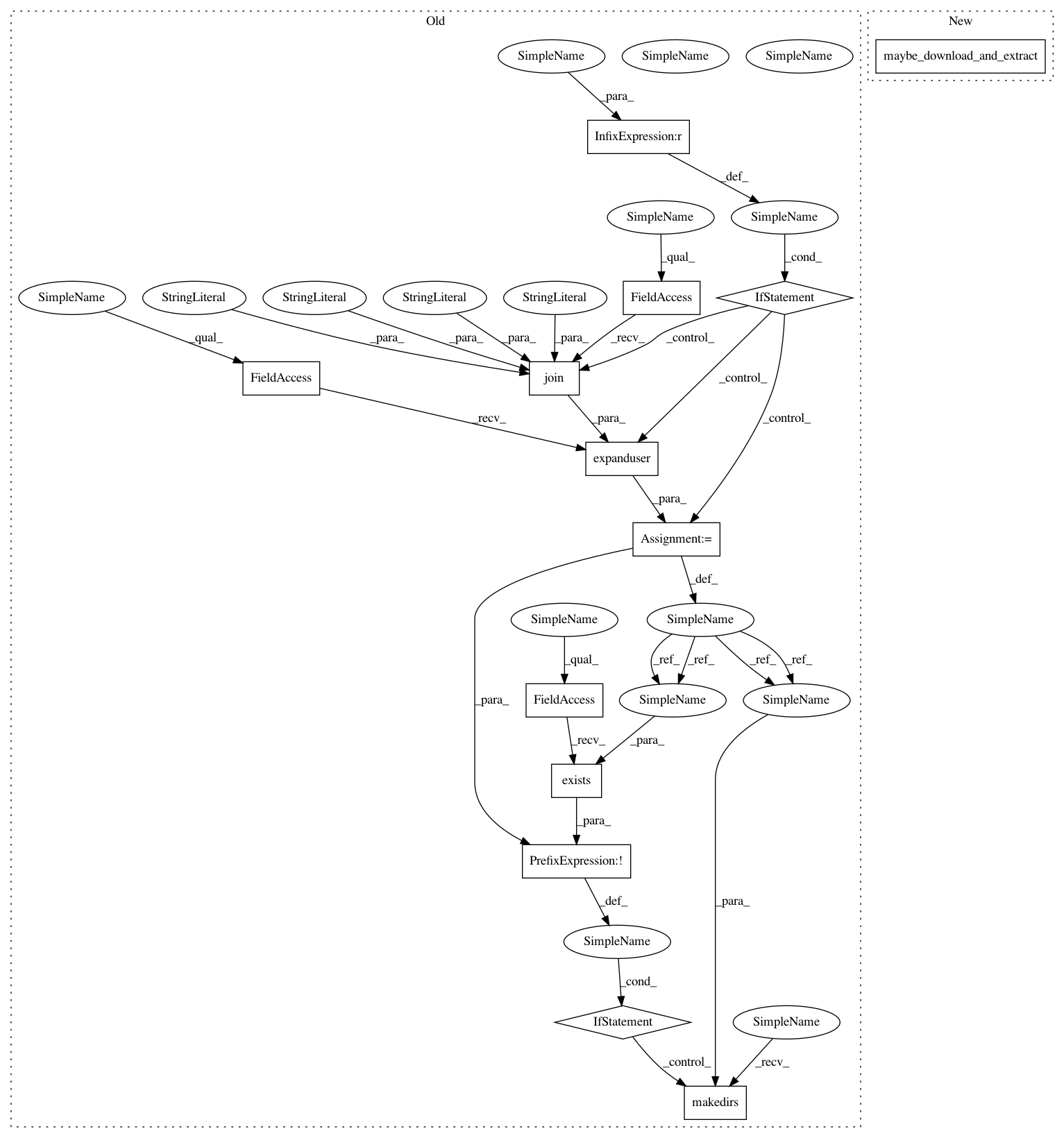
if path is None:
path = os.path.expanduser(os.path.join("~", ".tensorlayer", "datasets", "imdb"))
print("Load or Download imdb > {}".format(path))
if not os.path.exists(path):
os.makedirs(path)
url = "https://s3.amazonaws.com/text-datasets/"
def download_imbd(path, filename):
if not os.path.exists(os.path.join(path, filename)):
print("Downloading ...")
After Change
filename = "imdb.pkl"
url = "https://s3.amazonaws.com/text-datasets/"
maybe_download_and_extract(filename, path, url)
if filename.endswith(".gz"):
f = gzip.open(os.path.join(path, filename), "rb")
else:
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 13
Instances
Project Name: tensorlayer/tensorlayer
Commit Name: 4a8379e34e122217400e7d2cfe4e7829db0c40c7
Time: 2017-01-14
Author: joelkronander@gmail.com
File Name: tensorlayer/files.py
Class Name:
Method Name: load_imdb_dataset
Project Name: tensorlayer/tensorlayer
Commit Name: 4a8379e34e122217400e7d2cfe4e7829db0c40c7
Time: 2017-01-14
Author: joelkronander@gmail.com
File Name: tensorlayer/files.py
Class Name:
Method Name: load_imdb_dataset
Project Name: tensorlayer/tensorlayer
Commit Name: 4a8379e34e122217400e7d2cfe4e7829db0c40c7
Time: 2017-01-14
Author: joelkronander@gmail.com
File Name: tensorlayer/files.py
Class Name:
Method Name: load_matt_mahoney_text8_dataset
Project Name: tensorlayer/tensorlayer
Commit Name: 4a8379e34e122217400e7d2cfe4e7829db0c40c7
Time: 2017-01-14
Author: joelkronander@gmail.com
File Name: tensorlayer/files.py
Class Name:
Method Name: load_ptb_dataset