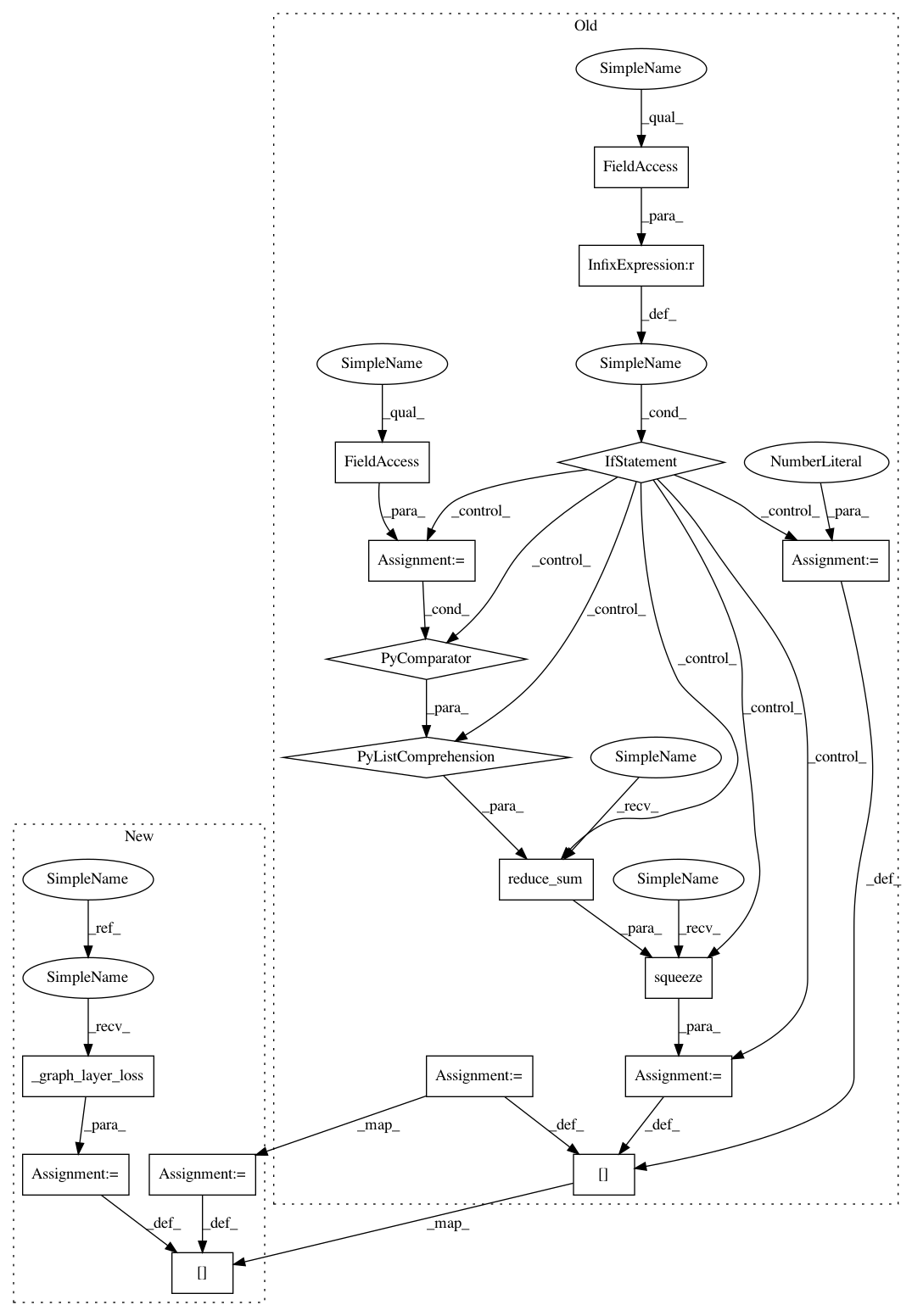
// Define regularization cost
self._log("Graph: Calculating loss and gradients...")
if self._reg_coeff is not None:
l2_cost = tf.squeeze(tf.reduce_sum(
[layer.regularization_coefficient * tf.nn.l2_loss(layer.weights) for layer in self._layers
if isinstance(layer, layers.fullyConnectedLayer)]))
else:
l2_cost = 0.0
// Define the cost function
if self._loss_fn == "yolo":
xx = tf.reshape(xx, [-1, self._grid_w * self._grid_h,
self._NUM_BOXES * 5 + self._NUM_CLASSES])
yolo_loss = self._yolo_loss_function(y, xx)
num_image_loss = tf.cast(tf.shape(xx)[0], tf.float32)
gpu_cost = tf.squeeze(yolo_loss / num_image_loss + l2_cost)
device_costs.append(yolo_loss)
// Set the optimizer and get the gradients from it
gradients, variables, global_grad_norm = self._graph_get_gradients(gpu_cost, optimizer)
device_gradients.append(gradients)
device_variables.append(variables)
// Average the gradients from each GPU and apply them
average_gradients = self._graph_average_gradients(device_gradients)
opt_variables = device_variables[0]
self._graph_ops["optimizer"] = self._graph_apply_gradients(average_gradients, opt_variables, optimizer)
// Average the costs and accuracies from each GPU
self._yolo_loss = 0
self._graph_ops["cost"] = tf.reduce_sum(device_costs) / self._batch_size + l2_cost
// Calculate test and validation accuracy (on a single device at Tensorflow"s discretion)
if self._testing:
After Change
self._graph_ops["merged"] = tf.summary.merge_all(key="custom_summaries")
def _assemble_graph(self):
with self._graph.as_default():
self._log("Assembling graph...")
self._log("Graph: Parsing dataset...")
with tf.device("device:cpu:0"): // Only do preprocessing on the CPU to limit data transfer between devices
self._graph_parse_data()
// For object detection, we need to also deserialize the labels before batching the datasets
def _deserialize_label(im, lab):
lab = tf.cond(tf.equal(tf.rank(lab), 0),
lambda: tf.reshape(lab, [1]),
lambda: lab)
sparse_lab = tf.string_split(lab, sep=" ")
lab_values = tf.strings.to_number(sparse_lab.values)
lab = tf.reshape(lab_values, [self._grid_w * self._grid_h, 5 + self._NUM_CLASSES])
return im, lab
// Batch the datasets and create iterators for them
self._train_dataset = self._train_dataset.map(_deserialize_label, num_parallel_calls=self._num_threads)
train_iter = self._batch_and_iterate(self._train_dataset, shuffle=True)
if self._testing:
self._test_dataset = self._test_dataset.map(_deserialize_label,
num_parallel_calls=self._num_threads)
test_iter = self._batch_and_iterate(self._test_dataset)
if self._validation:
self._val_dataset = self._val_dataset.map(_deserialize_label, num_parallel_calls=self._num_threads)
val_iter = self._batch_and_iterate(self._val_dataset)
if self._has_moderation:
train_mod_iter = self._batch_and_iterate(self._train_moderation_features)
if self._testing:
test_mod_iter = self._batch_and_iterate(self._test_moderation_features)
if self._validation:
val_mod_iter = self._batch_and_iterate(self._val_moderation_features)
// Create an optimizer object for all of the devices
optimizer = self._graph_make_optimizer()
// Set up the graph layers
self._log("Graph: Creating layer parameters...")
self._add_layers_to_graph()
// Do the forward pass and training output calcs on possibly multiple GPUs
device_costs = []
device_gradients = []
device_variables = []
for n, d in enumerate(self._get_device_list()): // Build a graph on either the CPU or all of the GPUs
with tf.device(d), tf.name_scope("tower_" + str(n)):
x, y = train_iter.get_next()
// Run the network operations
if self._has_moderation:
mod_w = train_mod_iter.get_next()
xx = self.forward_pass(x, deterministic=False, moderation_features=mod_w)
else:
xx = self.forward_pass(x, deterministic=False)
// Define regularization cost
self._log("Graph: Calculating loss and gradients...")
l2_cost = self._graph_layer_loss()
// Define the cost function
if self._loss_fn == "yolo":
xx = tf.reshape(xx, [-1, self._grid_w * self._grid_h,
self._NUM_BOXES * 5 + self._NUM_CLASSES])
yolo_loss = self._yolo_loss_function(y, xx)
num_image_loss = tf.cast(tf.shape(xx)[0], tf.float32)
gpu_cost = tf.squeeze(yolo_loss / num_image_loss + l2_cost)
device_costs.append(yolo_loss)
// Set the optimizer and get the gradients from it
gradients, variables, global_grad_norm = self._graph_get_gradients(gpu_cost, optimizer)
device_gradients.append(gradients)
device_variables.append(variables)
// Average the gradients from each GPU and apply them
average_gradients = self._graph_average_gradients(device_gradients)
opt_variables = device_variables[0]
self._graph_ops["optimizer"] = self._graph_apply_gradients(average_gradients, opt_variables, optimizer)
// Average the costs and accuracies from each GPU
self._yolo_loss = 0
self._graph_ops["cost"] = tf.reduce_sum(device_costs) / self._batch_size + l2_cost
// Calculate test and validation accuracy (on a single device at Tensorflow"s discretion)
if self._testing: