5651a0d052bcfd160b187828aa3d8d90652929fe,spacy/cli/ud/ud_run_test.py,,write_conllu,#Any#Any#,109
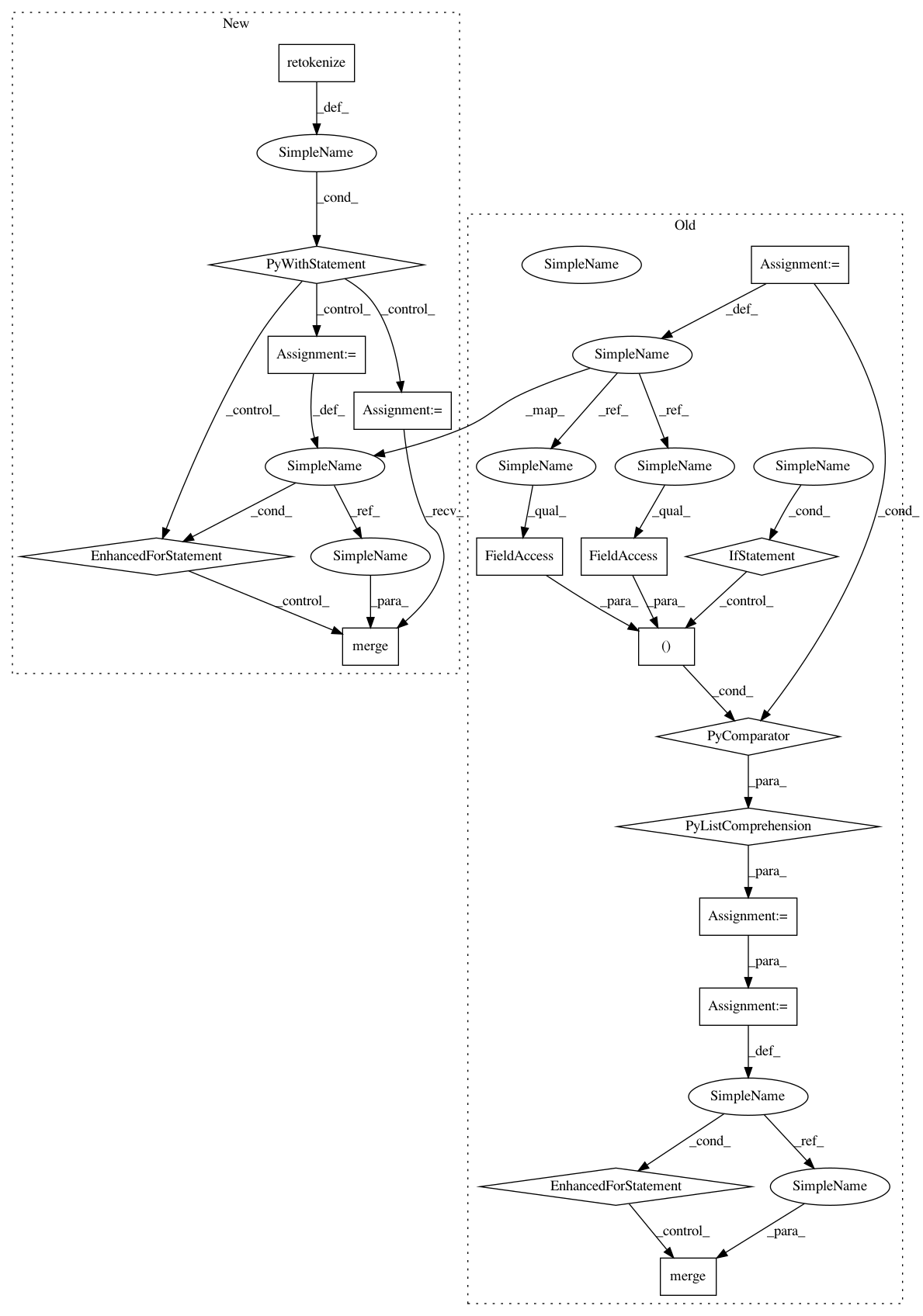
Before Change
for i, doc in enumerate(docs):
matches = merger(doc)
spans = [doc[start : end + 1] for _, start, end in matches]
offsets = [(span.start_char, span.end_char) for span in spans]
for start_char, end_char in offsets:
doc.merge(start_char, end_char)
// TODO: This shuldn"t be necessary? Should be handled in merge
for word in doc:
if word.i == word.head.i:
word.dep_ = "ROOT"
file_.write("// newdoc id = {i}\n".format(i=i))
After Change
for i, doc in enumerate(docs):
matches = merger(doc)
spans = [doc[start : end + 1] for _, start, end in matches]
with doc.retokenize() as retokenizer:
for span in spans:
retokenizer.merge(span)
// TODO: This shouldn"t be necessary? Should be handled in merge
for word in doc:
if word.i == word.head.i:
word.dep_ = "ROOT"
file_.write("// newdoc id = {i}\n".format(i=i))
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 17
Instances
Project Name: explosion/spaCy
Commit Name: 5651a0d052bcfd160b187828aa3d8d90652929fe
Time: 2019-02-15
Author: ines@ines.io
File Name: spacy/cli/ud/ud_run_test.py
Class Name:
Method Name: write_conllu
Project Name: explosion/spaCy
Commit Name: 5651a0d052bcfd160b187828aa3d8d90652929fe
Time: 2019-02-15
Author: ines@ines.io
File Name: spacy/pipeline/functions.py
Class Name:
Method Name: merge_subtokens
Project Name: explosion/spaCy
Commit Name: 5651a0d052bcfd160b187828aa3d8d90652929fe
Time: 2019-02-15
Author: ines@ines.io
File Name: spacy/cli/ud/ud_run_test.py
Class Name:
Method Name: write_conllu
Project Name: explosion/spaCy
Commit Name: 5651a0d052bcfd160b187828aa3d8d90652929fe
Time: 2019-02-15
Author: ines@ines.io
File Name: spacy/pipeline/functions.py
Class Name:
Method Name: merge_noun_chunks