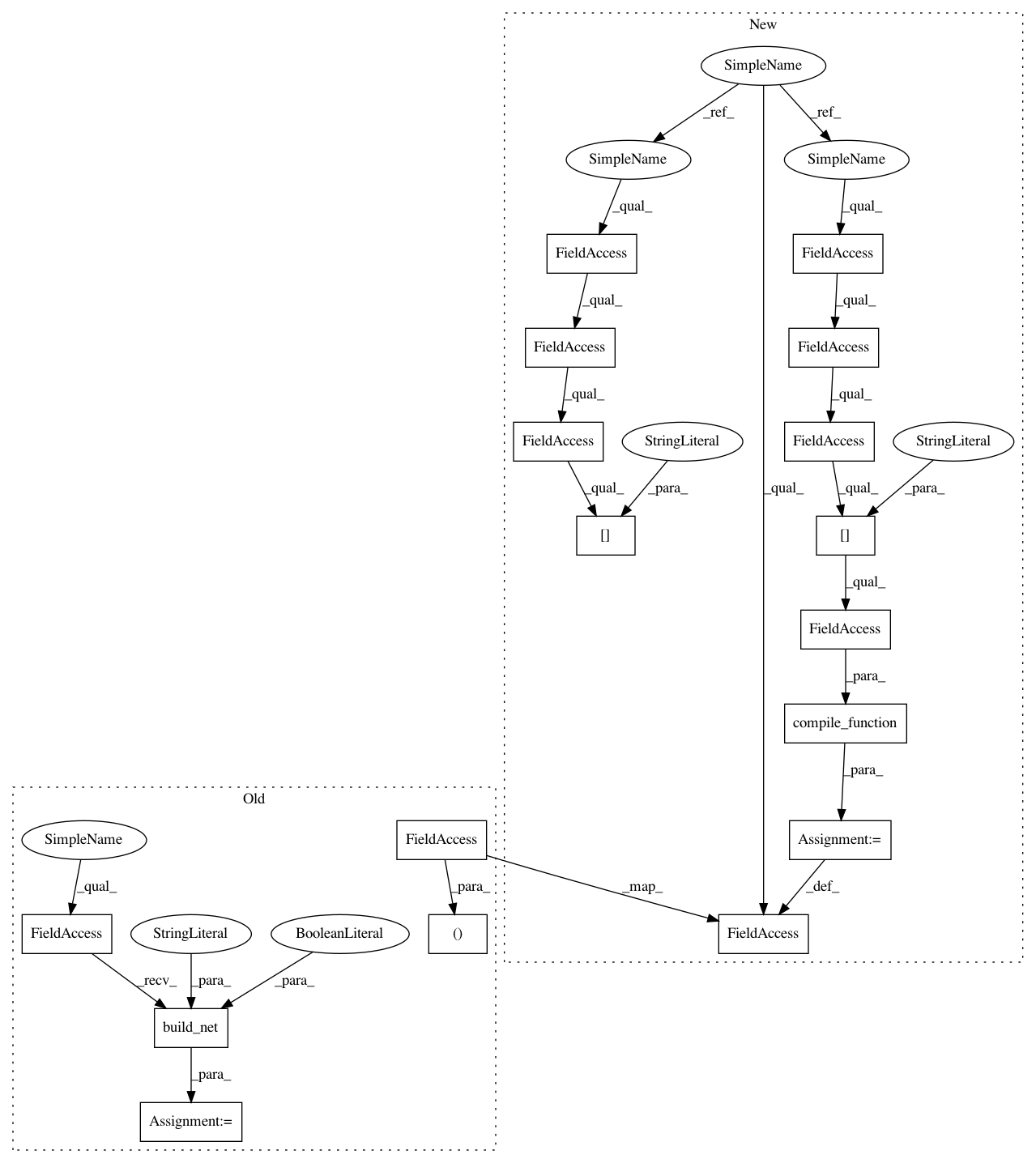
self.target_policy_f_prob_online = tensor_utils.compile_function(
inputs=[self.target_policy.model.networks["default"].input],
outputs=self.target_policy.model.networks["default"].outputs)
self.target_qf_f_prob_online, _, _, _ = self.qf.build_net(
trainable=False, name="target_qf")
self.target_qf2_f_prob_online, _, _, _ = self.qf2.build_net(
trainable=False, name="target_qf2")
// Set up target init and update functions
After Change
exploration_strategy=exploration_strategy)
@overrides
def init_opt(self):
Build the loss function and init the optimizer.
with tf.name_scope(self.name, "TD3"):
// Create target policy (actor) and qf (critic) networks
self.target_policy_f_prob_online = tensor_utils.compile_function(
inputs=[self.target_policy.model.networks["default"].input],
outputs=self.target_policy.model.networks["default"].outputs)
self.target_qf_f_prob_online = tensor_utils.compile_function(
inputs=self.target_qf.model.networks["default"].inputs,
outputs=self.target_qf.model.networks["default"].outputs)
self.target_qf2_f_prob_online = tensor_utils.compile_function(
inputs=self.target_qf2.model.networks["default"].inputs,
outputs=self.target_qf2.model.networks["default"].outputs)
// Set up target init and update functions
with tf.name_scope("setup_target"):