@dtypes(*torch.testing.get_all_dtypes())
def test_float_scalarlist(self, device, dtype):
for N in N_values:
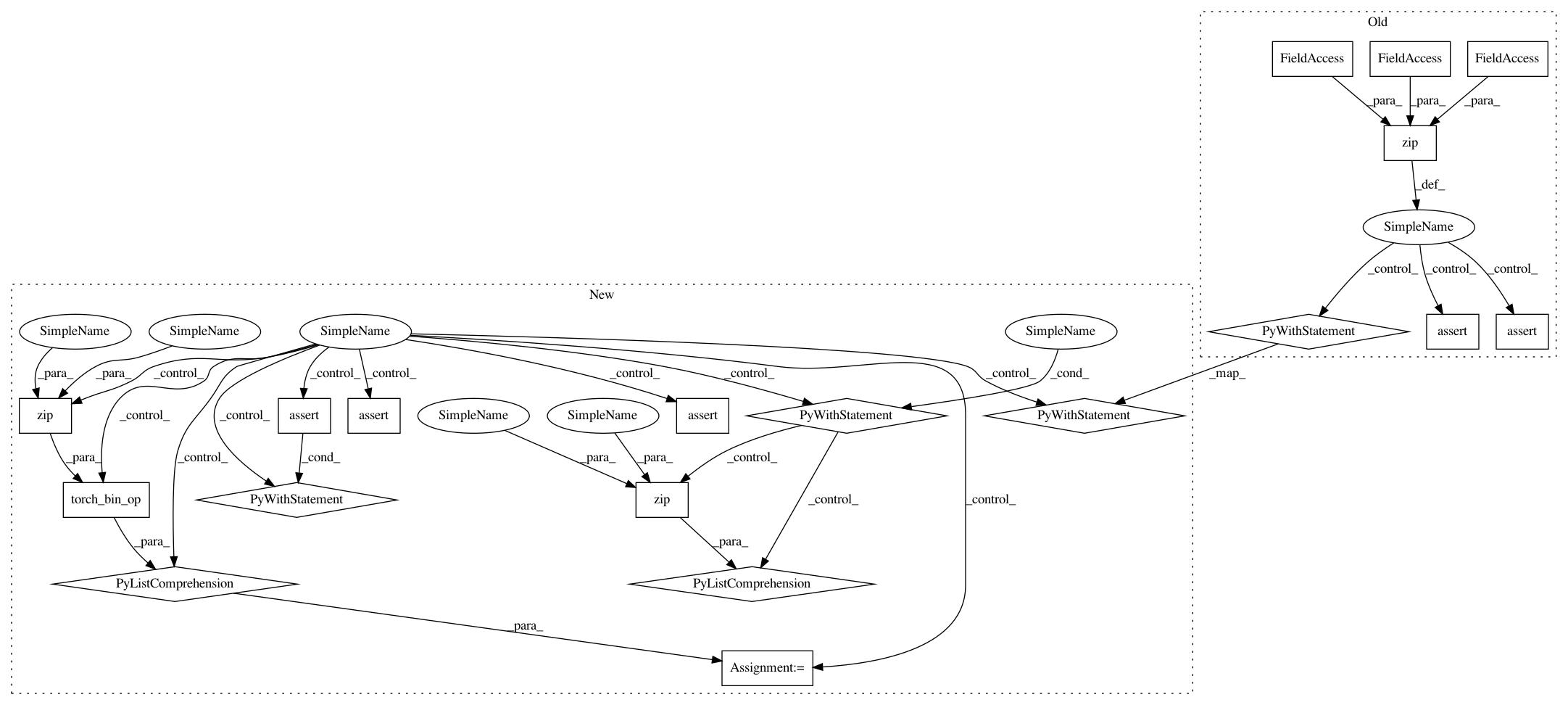
for foreach_bin_op, foreach_bin_op_, torch_bin_op in zip(self.foreach_bin_ops,
self.foreach_bin_ops_,
self.torch_bin_ops):
tensors = self._get_test_data(device, dtype, N)
scalars = [1.1 for _ in range(N)]
// If incoming dtype is float16 or bfloat16, runs in float32 and casts output back to dtype.
control_dtype = torch.float32 if (self.device_type == "cuda" and
(dtype is torch.float16 or dtype is torch.bfloat16)) else dtype
expected = [torch_bin_op(t.to(dtype=control_dtype),
s) for t, s in zip(tensors, scalars)]
if (dtype is torch.float16 or dtype is torch.bfloat16):
expected = [e.to(dtype=dtype) for e in expected]
// we dont support bool and complex types on CUDA for now
if (dtype in torch.testing.get_all_complex_dtypes() or dtype == torch.bool) and self.device_type == "cuda":
with self.assertRaisesRegex(RuntimeError, "not implemented for"):
foreach_bin_op_(tensors, scalars)
with self.assertRaisesRegex(RuntimeError, "not implemented for"):
foreach_bin_op(tensors, scalars)
return
res = foreach_bin_op(tensors, scalars)
if dtype == torch.bool:
// see TODO[Fix scalar list]
self.assertEqual(res, [torch_bin_op(t.to(torch.float32), s) for t, s in zip(tensors, scalars)])with self.assertRaisesRegex(RuntimeError, "result type Float can"t be cast to the desired output type"):
foreach_bin_op_(tensors, scalars)
return
if dtype in torch.testing.integral_types() and self.device_type == "cuda":
// see TODO[Fix scalar list]
self.assertEqual(res, [e.to(dtype) for e in expected])
foreach_bin_op_(tensors, scalars)
self.assertEqual(tensors, res)
return