194b2c59307ea8f46b55840d4fd92bf85173f168,textClassification/wrapper.py,Classifier,predict,#Classifier#Any#Any#,88
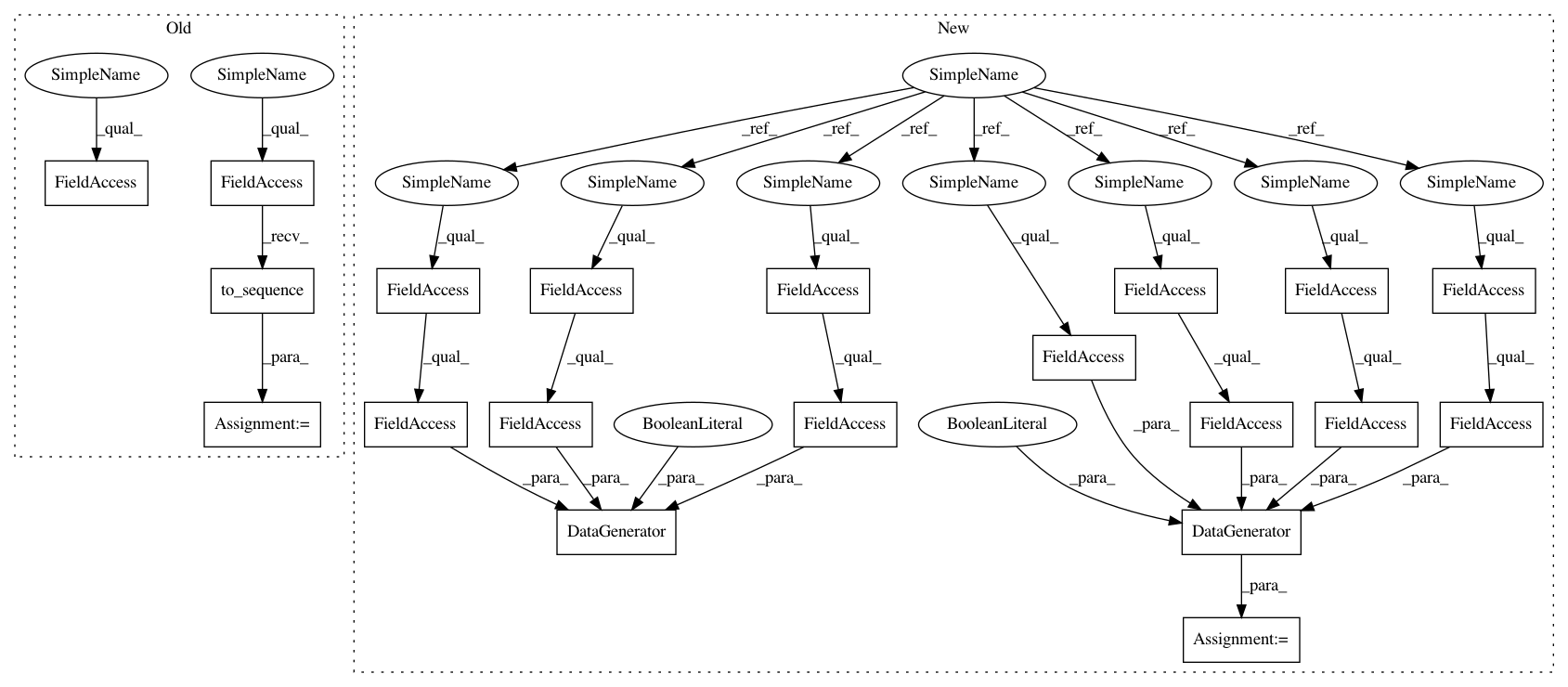
Before Change
if self.model_config.fold_number is 1:
if self.model is not None:
//classifier = Classifier(self.model, preprocessor=self.p)
x_t = self .p.to_sequence(texts, maxlen=300)
result = predict(self.model, x_t)
else:
raise (OSError("Could not find a model."))
else:
if self.models is not None:
x_t = self.p.to_sequence(texts, maxlen=300)
result = predict_folds(self.models, x_t)
else:
raise (OSError("Could not find nfolds models."))
if output_format is "json":After Change
self.models = train_folds(x_train, y_train, self.model_config, self.training_config, self.embeddings)
// classification
def predict(self , texts, output_format="json"):
if self.model_config.fold_number is 1:
if self.model is not None:
//classifier = Classifier(self.model, preprocessor=self.p)
//x_t = self.p.to_sequence(texts, maxlen=300)
predict_generator = DataGenerator(texts, None, batch_size=self.model_config.batch_size,
maxlen=self.model_config.maxlen, list_classes=self.model_config.list_classes,
embed_size=self.model_config.word_embedding_size, embeddings=self.embeddings, shuffle=False)
//x_t = self.p.to_vector(texts, self.embeddings, maxlen=self.model_config.maxlen, embed_size=self.model_config.word_embedding_size)
result = predict(self.model, predict_generator)
else:
raise (OSError("Could not find a model."))
else:
if self.models is not None:
//x_t = self.p.to_sequence(texts, maxlen=300)
//x_t = self.p.to_vector(texts, self.embeddings, maxlen=self.model_config.maxlen, embed_size=self.model_config.word_embedding_size)
predict_generator = DataGenerator(texts, None, batch_size=self.model_config.batch_size,
maxlen=self.model_config.maxlen, list_classes=self.model_config.list_classes,
embed_size=self.model_config.word_embedding_size, embeddings=self.embeddings, shuffle=False)
result = predict_folds(self.models, predict_generator)
else:
raise (OSError("Could not find nfolds models."))In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 20
Instances Project Name: kermitt2/delft
Commit Name: 194b2c59307ea8f46b55840d4fd92bf85173f168
Time: 2018-05-03
Author: patrice.lopez@science-miner.com
File Name: textClassification/wrapper.py
Class Name: Classifier
Method Name: predict
Project Name: kermitt2/delft
Commit Name: 194b2c59307ea8f46b55840d4fd92bf85173f168
Time: 2018-05-03
Author: patrice.lopez@science-miner.com
File Name: textClassification/wrapper.py
Class Name: Classifier
Method Name: predict
Project Name: kermitt2/delft
Commit Name: 194b2c59307ea8f46b55840d4fd92bf85173f168
Time: 2018-05-03
Author: patrice.lopez@science-miner.com
File Name: textClassification/wrapper.py
Class Name: Classifier
Method Name: eval
Project Name: kermitt2/delft
Commit Name: 194b2c59307ea8f46b55840d4fd92bf85173f168
Time: 2018-05-03
Author: patrice.lopez@science-miner.com
File Name: textClassification/wrapper.py
Class Name: Classifier
Method Name: train