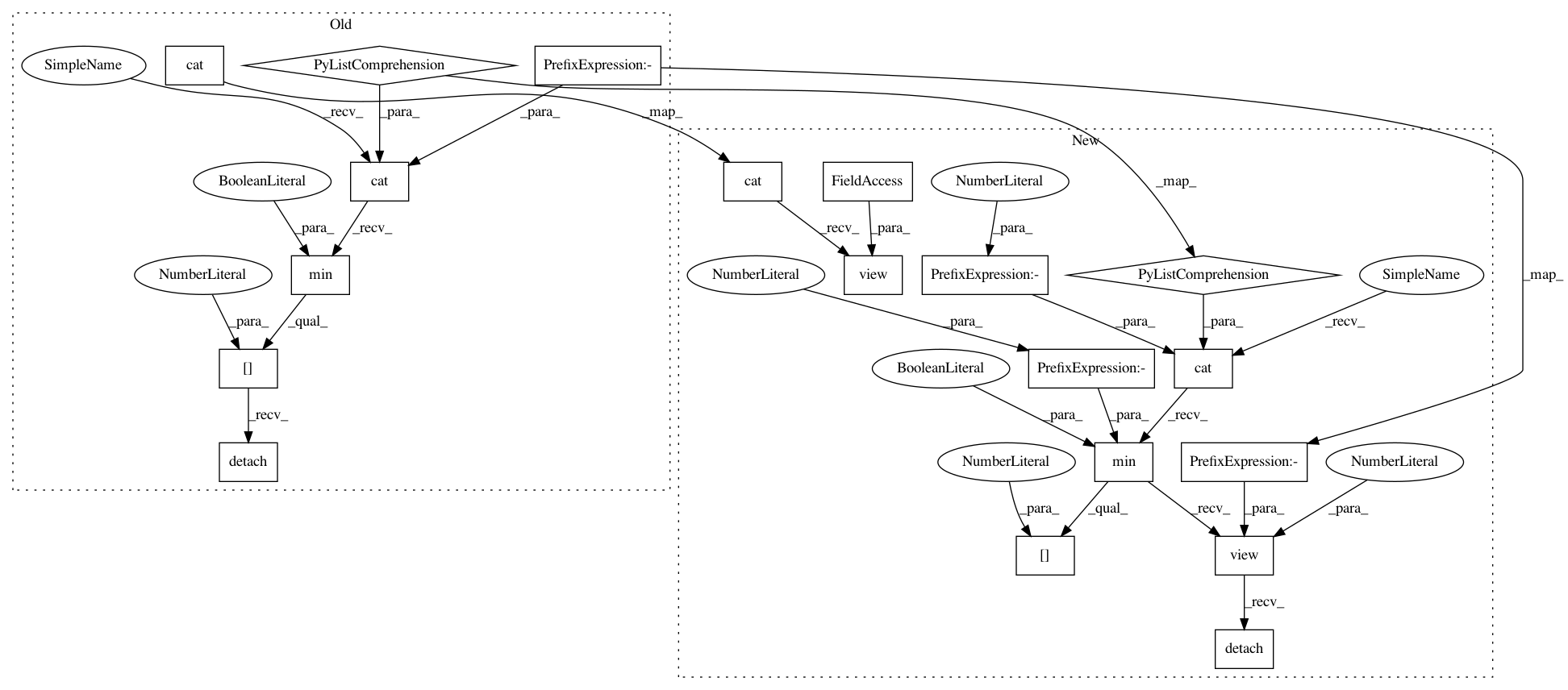
x(states_t, actions_tp0).squeeze_(dim=3)
for x in self.critics
]
q_values_tp0_min = torch.cat(q_values_tp0, dim=-1).min(dim=-1)[0]
// For now we use the same log_pi for each head.
policy_loss = torch.mean(logprob_tp0[:, None] - q_values_tp0_min)
// critic loss
actions_tp1, logprob_tp1 = self.actor(states_tp1, logprob=True)
logprob_tp1 = logprob_tp1 / self.reward_scale
q_values_t = [
x(states_t, actions_t).squeeze_(dim=3)
for x in self.critics
]
// B x num_heads x num_critics
q_values_tp1 = torch.cat([
x(states_tp1, actions_tp1).squeeze_(dim=3)
for x in self.target_critics
], dim=-1)
// B x num_heads x 1
q_values_tp1 = q_values_tp1.min(dim=-1, keepdim=True)[0].detach()
// Again, we use the same log_pi for each head.
logprob_tp1 = logprob_tp1[:, None, None] // B x 1 x 1
// B x num_heads x 1
After Change
// [{bs * num_heads}; num_critics] -> min over all critics
// [{bs * num_heads};]
q_values_tp0_min = (
torch.cat(q_values_tp0, dim=-1)
.view(-1, self._num_critics)
.min(dim=1)[0]
)
// For now we use the same log_pi for each head.
policy_loss = torch.mean(logprob_tp0[:, None] - q_values_tp0_min)
// critic loss
// [bs; action_size]
actions_tp1, logprob_tp1 = self.actor(states_tp1, logprob=True)
logprob_tp1 = logprob_tp1 / self.reward_scale
// {num_critics} * [bs; num_heads; 1, 1]
// -> many-heads view transform
// {num_critics} * [{bs * num_heads}; 1]
q_values_t = [
x(states_t, actions_t)
.view(-1, 1)
for x in self.critics
]
// {num_critics} * [bs; num_heads; 1]
q_values_tp1 = [
x(states_tp1, actions_tp1).squeeze_(dim=3)
for x in self.target_critics
]
// {num_critics} * [bs; num_heads; 1] -> concat
// [bs; num_heads; num_critics] -> min over all critics
// [bs; num_heads; 1]
q_values_tp1 = (
torch.cat(q_values_tp1, dim=-1)
.min(dim=-1, keepdim=True)[0]
)
// Again, we use the same log_pi for each head.
logprob_tp1 = logprob_tp1[:, None, None] // B x 1 x 1
// [bs; num_heads; 1]
v_target_tp1 = q_values_tp1 - logprob_tp1
// [bs; num_heads; 1] -> many-heads view transform
// [{bs * num_heads}; 1]
q_target_t = (
rewards_t + (1 - done_t) * gammas * v_target_tp1
).view(-1, 1).detach()
value_loss = [
self.critic_criterion(x, q_target_t).mean() for x in q_values_t
]