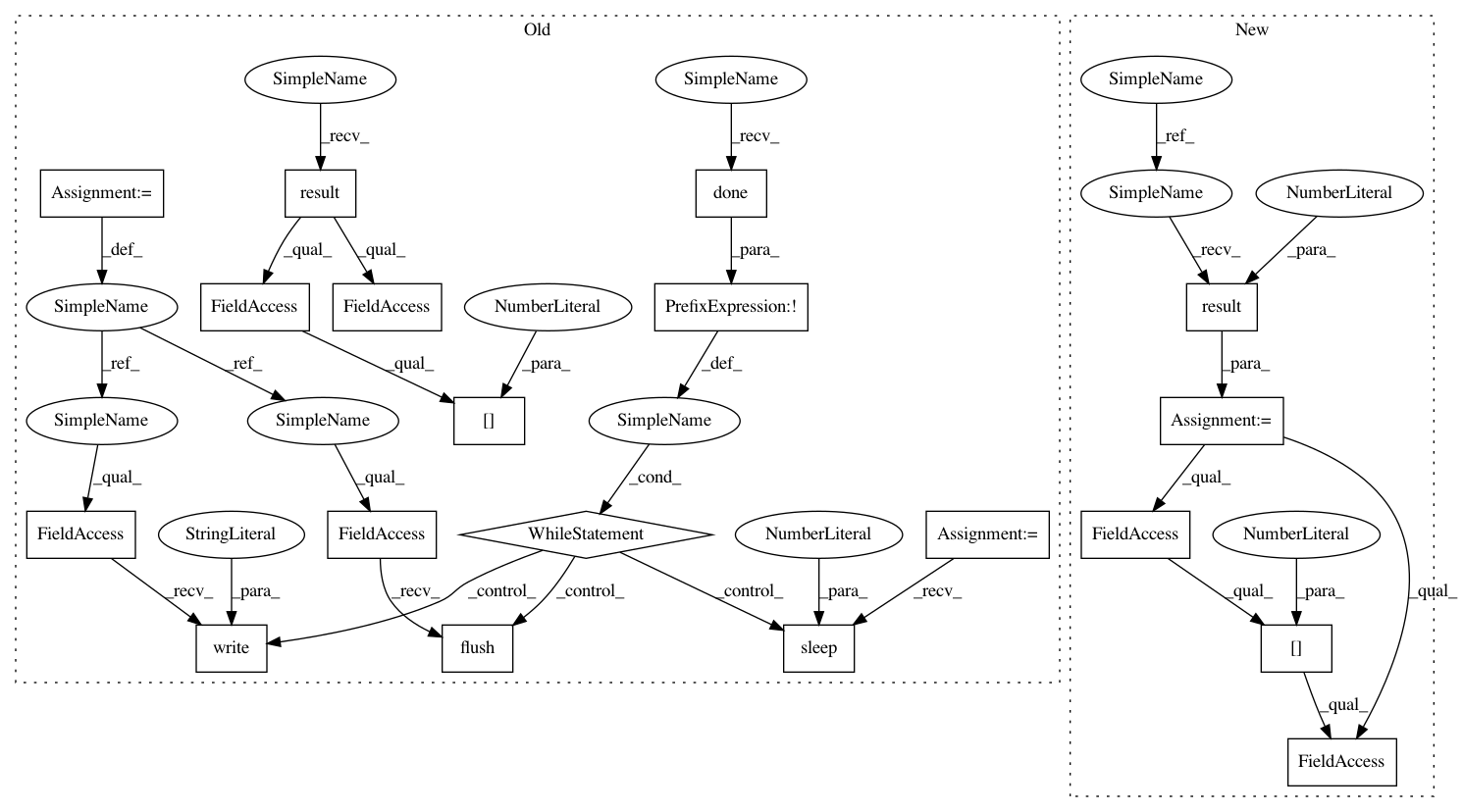
operation = video_client.annotate_video(path, features)
print("\nProcessing video for explicit content annotations:")
while not operation.done():
sys.stdout.write(".")
sys.stdout.flush()
time.sleep(15)
print("\nFinished processing.")
// first result is retrieved because a single video was processed
explicit_annotation = (operation.result().annotation_results[0].
explicit_annotation)
likely_string = ("Unknown", "Very unlikely", "Unlikely", "Possible",
"Likely", "Very likely")
for frame in explicit_annotation.frames:
frame_time = frame.time_offset.seconds + frame.time_offset.nanos / 1e9
print("Time: {}s".format(frame_time))
print("\tpornography: {}".format(
After Change
video_client = videointelligence.VideoIntelligenceServiceClient()
features = [videointelligence.enums.Feature.EXPLICIT_CONTENT_DETECTION]
operation = video_client.annotate_video(path, features=features)
print("\nProcessing video for explicit content annotations:")
result = operation.result(timeout=90)
print("\nFinished processing.")
likely_string = ("Unknown", "Very unlikely", "Unlikely", "Possible",
"Likely", "Very likely")
// first result is retrieved because a single video was processed
for frame in result.annotation_results[0].explicit_annotation.frames:
frame_time = frame.time_offset.seconds + frame.time_offset.nanos / 1e9
print("Time: {}s".format(frame_time))
print("\tpornography: {}".format(