66f8f9d4a0476f84a130f9e7ba5c7f69f4da02e4,spacy/lang/ja/__init__.py,Japanese,make_doc,#Japanese#Any#,35
Before Change
Defaults = JapaneseDefaults
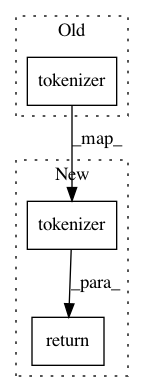
def make_doc(self, text):
words = self.tokenizer(text)
return Doc(self.vocab, words=words, spaces=[False]*len(words))
__all__ = ["Japanese"]
After Change
Defaults = JapaneseDefaults
def make_doc(self, text):
return self.tokenizer(text)
__all__ = ["Japanese"]
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 3
Instances
Project Name: explosion/spaCy
Commit Name: 66f8f9d4a0476f84a130f9e7ba5c7f69f4da02e4
Time: 2017-10-24
Author: ines@ines.io
File Name: spacy/lang/ja/__init__.py
Class Name: Japanese
Method Name: make_doc
Project Name: allenai/allennlp
Commit Name: fb73633a42053e8a0b2ce71448bad938f33a8442
Time: 2017-08-30
Author: mattg@allenai.org
File Name: allennlp/data/tokenizers/word_splitter.py
Class Name: SpacyWordSplitter
Method Name: split_words
Project Name: explosion/spaCy
Commit Name: 0b9a5f4074f2b6f5ad3322234a82ac921fe1f358
Time: 2019-11-11
Author: adrianeboyd@gmail.com
File Name: spacy/lang/zh/__init__.py
Class Name: Chinese
Method Name: make_doc