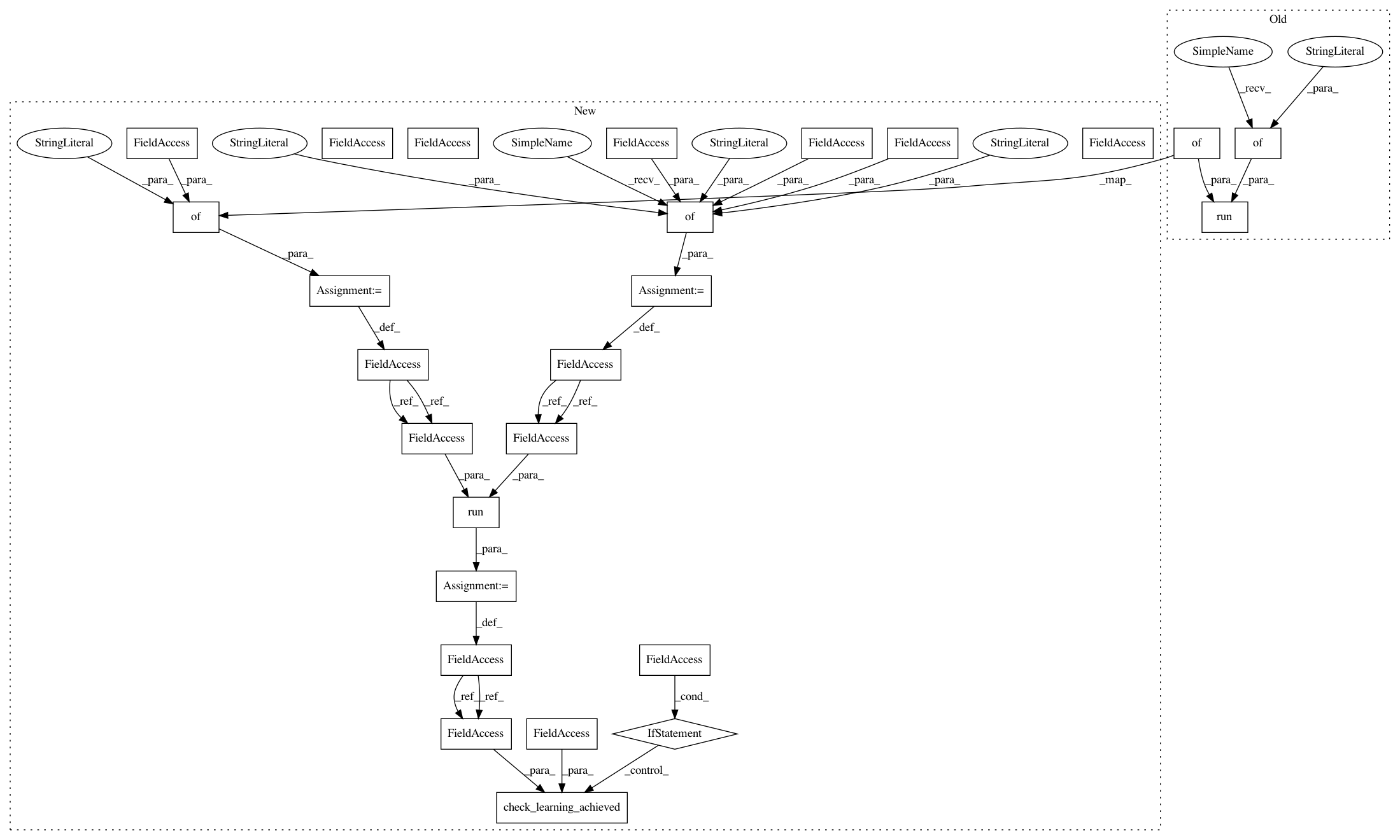
57544b1ff9f97d4da9f64d25c8ea5a3d8d247ffc,rllib/examples/centralized_critic_2.py,,,#,110
Before Change
"opponent_obs": Discrete(6),
"opponent_action": Discrete(2),
})
tune.run(
"PPO",
stop={
"timesteps_total": args.stop,
"episode_reward_mean": 7.99,
},
config={
"env": TwoStepGame,
"batch_mode": "complete_episodes",
"callbacks": FillInActions,
"num_workers": 0,
"multiagent": {
"policies": {
"pol1": (None, observer_space, action_space, {}),
"pol2": (None, observer_space, action_space, {}),
},
"policy_mapping_fn": lambda x: "pol1" if x == 0 else "pol2",
"observation_fn": central_critic_observer,
},
"model": {
"custom_model": "cc_model",
},
})
After Change
"opponent_action": Discrete(2),
})
config = {
"env": TwoStepGame,
"batch_mode": "complete_episodes",
"callbacks": FillInActions,
"num_workers": 0,
"multiagent": {
"policies": {
"pol1": (None, observer_space, action_space, {}),
"pol2": (None, observer_space, action_space, {}),
},
"policy_mapping_fn": lambda x: "pol1" if x == 0 else "pol2",
"observation_fn": central_critic_observer,
},
"model": {
"custom_model": "cc_model",
},
"use_pytorch": args.torch,
}
stop = {
"training_iteration": args.stop_iters,
"timesteps_total": args.stop_timesteps,
"episode_reward_mean": args.stop_reward,
}
results = tune.run("PPO", config=config, stop=stop)
if args.as_test:
check_learning_achieved(results, args.stop_reward)
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 26
Instances
Project Name: ray-project/ray
Commit Name: 57544b1ff9f97d4da9f64d25c8ea5a3d8d247ffc
Time: 2020-05-11
Author: sven@anyscale.io
File Name: rllib/examples/centralized_critic_2.py
Class Name:
Method Name:
Project Name: ray-project/ray
Commit Name: 57544b1ff9f97d4da9f64d25c8ea5a3d8d247ffc
Time: 2020-05-11
Author: sven@anyscale.io
File Name: rllib/examples/custom_env.py
Class Name:
Method Name:
Project Name: ray-project/ray
Commit Name: 57544b1ff9f97d4da9f64d25c8ea5a3d8d247ffc
Time: 2020-05-11
Author: sven@anyscale.io
File Name: rllib/examples/two_trainer_workflow.py
Class Name:
Method Name: