e78aa611274f9a946ae7243fe68427b55d5ddd18,python/tvm/topi/cuda/conv2d_winograd.py,,winograd_cuda,#Any#Any#Any#Any#Any#Any#Any#Any#,41
Before Change
name="output",
tag="conv2d_nchw_winograd",
)
cfg.add_flop(2 * N * CO * H * W * CI * KH * KW)
return output
After Change
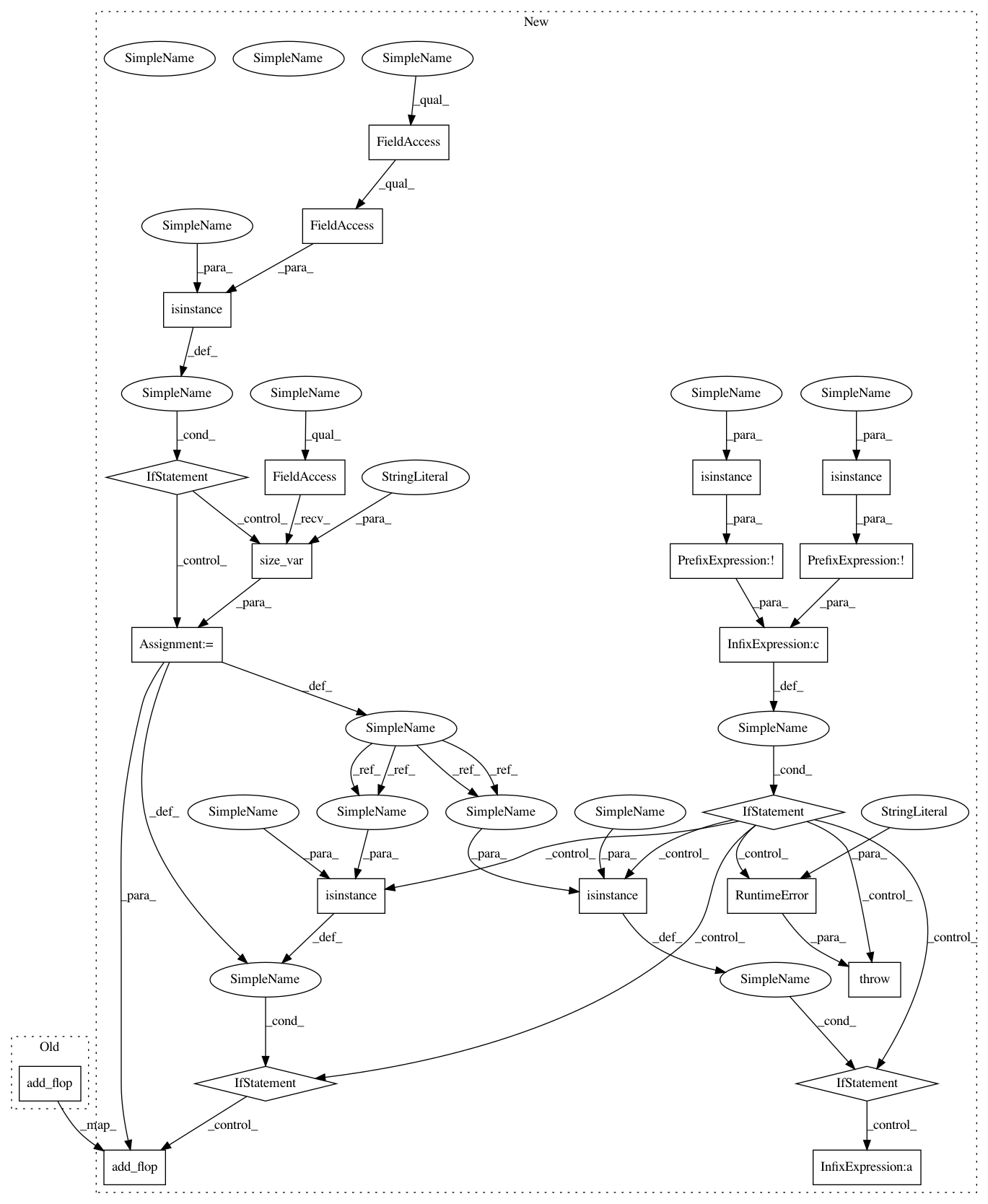
N, CI, H, W = get_const_tuple(data.shape)
if isinstance(N, tvm.tir.Any):
N = tvm.te.size_var("n")
if not isinstance(H, int) or not isinstance(W, int):
raise RuntimeError(
"cuda winograd conv2d doesn"t support dynamic input\
height or width."
)
if isinstance(dilation, int):
dilation_h = dilation_w = dilation
else:
dilation_h, dilation_w = dilation
HSTR, WSTR = (strides, strides) if isinstance(strides, int) else strides
if not pre_computed: // kernel tensor is raw tensor, do strict check
if dilation_h != 1 or dilation_w != 1:
kernel = nn.dilate(kernel, (1, 1, dilation_h, dilation_w))
CO, CI, KH, KW = get_const_tuple(kernel.shape)
alpha = KW + tile_size - 1
assert HSTR == 1 and WSTR == 1 and KH == KW
else:
// kernel tensor is pre-transfomred. this op is created by alter op layout.
// dilation is not supported
alpha, _, CI, CO = get_const_tuple(kernel.shape)
KH = KW = alpha + 1 - tile_size
assert HSTR == 1 and WSTR == 1 and dilation_h == 1 and dilation_w == 1
pt, pl, pb, pr = nn.get_pad_tuple(padding, (KH, KW))
data_pad = nn.pad(data, (0, 0, pt, pl), (0, 0, pb, pr), name="data_pad")
r = KW
m = tile_size
A, B, G = winograd_transform_matrices(m, r, out_dtype)
H = (H + pt + pb - KH) // HSTR + 1
W = (W + pl + pr - KW) // WSTR + 1
nH, nW = (H + m - 1) // m, (W + m - 1) // m
P = N * nH * nW if isinstance(N, int) else nH * nW
// transform kernel
if not pre_computed:
r_kh = te.reduce_axis((0, KH), name="r_kh")
r_kw = te.reduce_axis((0, KW), name="r_kw")
kernel_pack = te.compute(
(alpha, alpha, CI, CO),
lambda eps, nu, ci, co: te.sum(
kernel[co][ci][r_kh][r_kw] * G[eps][r_kh] * G[nu][r_kw], axis=[r_kh, r_kw]
),
name="kernel_pack",
)
else:
kernel_pack = kernel
idxdiv = tvm.tir.indexdiv
idxmod = tvm.tir.indexmod
// pack input tile
input_tile = te.compute(
(CI, P, alpha, alpha),
lambda c, p, eps, nu: data_pad[idxdiv(p, (nH * nW))][c][
idxmod(idxdiv(p, nW), nH) * m + eps
][idxmod(p, nW) * m + nu],
name="d",
)
// transform data
r_a = te.reduce_axis((0, alpha), "r_a")
r_b = te.reduce_axis((0, alpha), "r_a")
data_pack = te.compute(
(alpha, alpha, CI, P),
lambda eps, nu, ci, p: te.sum(
input_tile[ci][p][r_a][r_b] * B[r_a][eps] * B[r_b][nu], axis=[r_a, r_b]
),
name="data_pack",
)
// do batch gemm
ci = te.reduce_axis((0, CI), name="ci")
bgemm = te.compute(
(alpha, alpha, CO, P),
lambda eps, nu, co, p: te.sum(
kernel_pack[eps][nu][ci][co] * data_pack[eps][nu][ci][p], axis=[ci]
),
name="bgemm",
)
// inverse transform
r_a = te.reduce_axis((0, alpha), "r_a")
r_b = te.reduce_axis((0, alpha), "r_a")
inverse = te.compute(
(CO, P, m, m),
lambda co, p, vh, vw: te.sum(
bgemm[r_a][r_b][co][p] * A[r_a][vh] * A[r_b][vw], axis=[r_a, r_b]
),
name="inverse",
)
// output
output = te.compute(
(N, CO, H, W),
lambda n, co, h, w: inverse[
co, n * nH * nW + idxdiv(h, m) * nW + idxdiv(w, m), idxmod(h, m), idxmod(w, m)
],
name="output",
tag="conv2d_nchw_winograd",
)
if isinstance(N, int):
cfg.add_flop(2 * N * CO * H * W * CI * KH * KW)
return output
def schedule_winograd_cuda(cfg, s, output, pre_computed):
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 22
Instances
Project Name: apache/incubator-tvm
Commit Name: e78aa611274f9a946ae7243fe68427b55d5ddd18
Time: 2020-10-01
Author: 5145158+zhiics@users.noreply.github.com
File Name: python/tvm/topi/cuda/conv2d_winograd.py
Class Name:
Method Name: winograd_cuda
Project Name: apache/incubator-tvm
Commit Name: 1d6ee60e69ec3bca31adcaedc30aff1eb80170d2
Time: 2020-09-18
Author: kevinthesunwy@gmail.com
File Name: python/tvm/topi/arm_cpu/conv2d.py
Class Name:
Method Name: _decl_winograd
Project Name: apache/incubator-tvm
Commit Name: e78aa611274f9a946ae7243fe68427b55d5ddd18
Time: 2020-10-01
Author: 5145158+zhiics@users.noreply.github.com
File Name: python/tvm/topi/cuda/conv2d_nhwc_winograd.py
Class Name:
Method Name: nhwc_winograd_cuda
Project Name: apache/incubator-tvm
Commit Name: e78aa611274f9a946ae7243fe68427b55d5ddd18
Time: 2020-10-01
Author: 5145158+zhiics@users.noreply.github.com
File Name: python/tvm/topi/cuda/conv2d_winograd.py
Class Name:
Method Name: winograd_cuda