td = tf.subtract(self.v_target, self.v, name="TD_error")
with tf.name_scope("c_loss"):
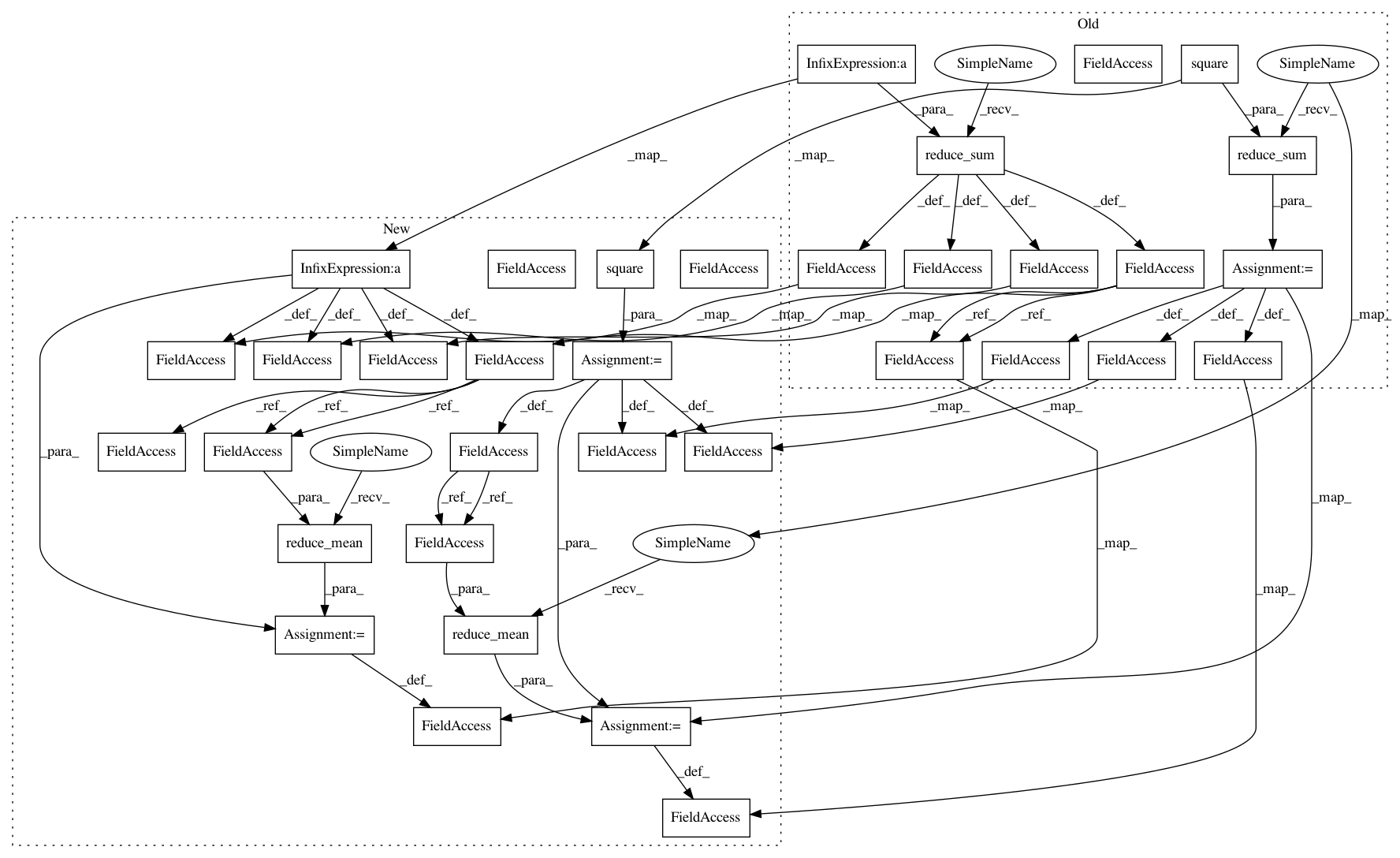
self.c_loss = tf.reduce_sum(tf.square(td))
with tf.name_scope("wrap_a_out"):
mu, sigma = mu * A_BOUND[1], sigma + 1e-6
self.test = sigma[0]
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope("a_loss"):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() // encourage exploration
self.exp_v = tf.reduce_sum(ENTROPY_BETA * entropy + exp_v)self.a_loss = -self.exp_v
with tf.name_scope("choose_a"): // use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), A_BOUND[0], A_BOUND[1])
with tf.name_scope("local_grad"):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + "/actor")
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + "/critic")
self.a_grads = tf.gradients(self.a_loss, self.a_params) // get local gradients
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope("sync"):
with tf.name_scope("pull"):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope("push"):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, n_a):
w_init = tf.random_normal_initializer(0., .01)
After Change
td = tf.subtract(self.v_target, self.v, name="TD_error")
with tf.name_scope("c_loss"):
self.c_losses = tf.square(td) // shape (None, 1), use this to get sum of gradients over batch
self.c_loss = tf.reduce_mean(self.c_losses)
with tf.name_scope("wrap_a_out"):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
self.test = sigma[0]
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope("a_loss"):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() // encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_vself.a_losses = -self.exp_v // shape (None, 1), use this to get sum of gradients over batch
self.a_loss = tf.reduce_mean(self.a_losses)
with tf.name_scope("choose_a"): // use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), A_BOUND[0], A_BOUND[1])
with tf.name_scope("local_grad"):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + "/actor")
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + "/critic")
self.a_grads = tf.gradients(self.a_losses, self.a_params) // use losses will give accumulated sum of gradients
self.c_grads = tf.gradients(self.c_losses, self.c_params)
with tf.name_scope("sync"):
with tf.name_scope("pull"):
self.pull_a_params_op = [l_p.assign(tf.clip_by_value(g_p, -5., 5.)) for l_p, g_p in
zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(tf.clip_by_value(g_p, -5., 5.)) for l_p, g_p in
zip(self.c_params, globalAC.c_params)]
with tf.name_scope("push"):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, n_a):
w_init = tf.random_normal_initializer(0., .01)