1522baaa3d0ced610ef1597ec8ef20d2fc0f29c0,scripts/speaker_embedding.py,,train,#Any#Any#Any#,79
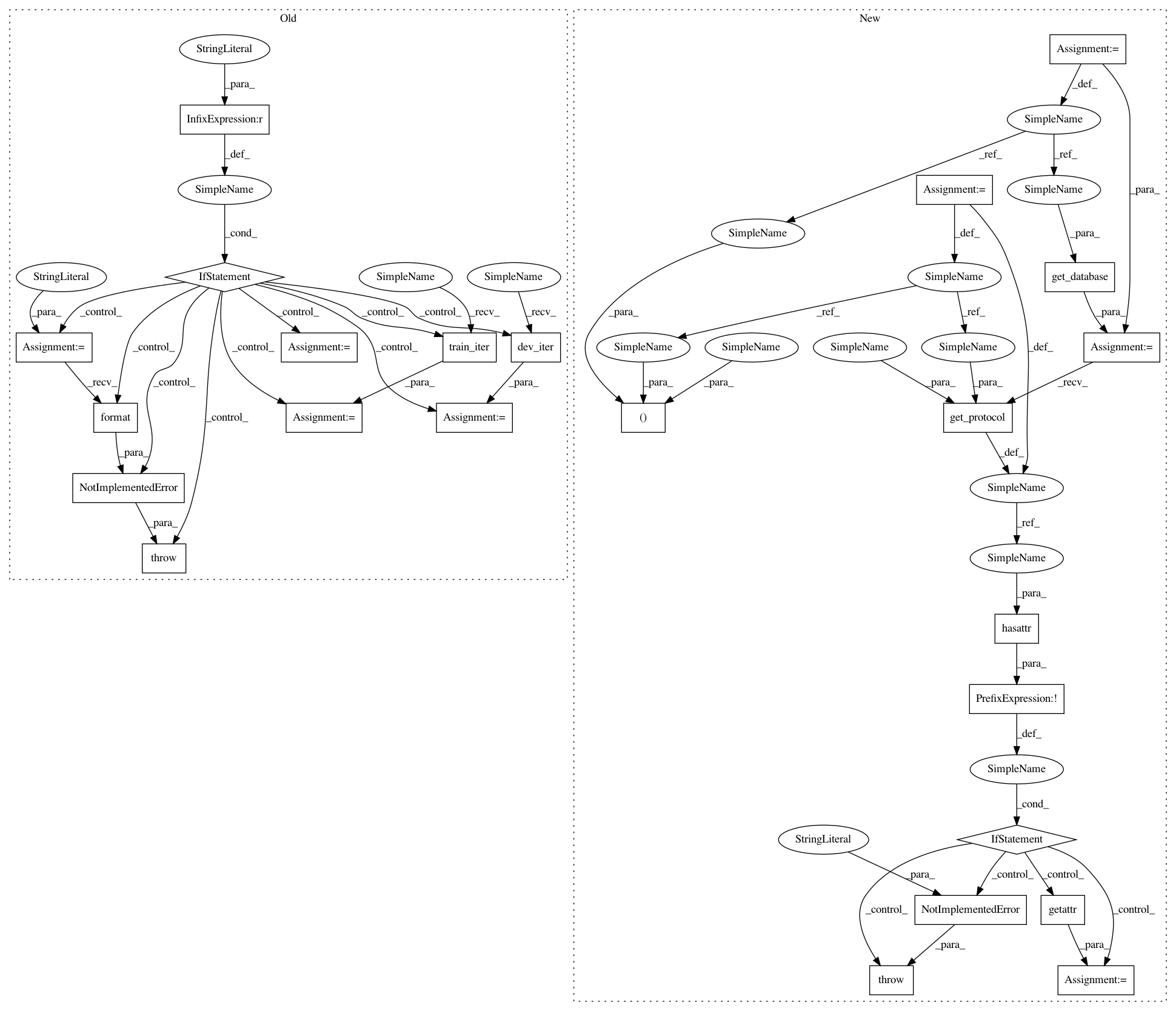
Before Change
// -- DATASET --
dataset, subset = dataset.split(".")
if dataset != "etape":
msg = "{dataset} dataset is not supported."
raise NotImplementedError(msg.format(dataset=dataset))
protocol = Etape(dataset_dir)
if subset == "train":
file_generator = protocol.train_iter()
elif subset == "dev":
file_generator = protocol.dev_iter()
else:
msg = "Training on {subset} subset is not allowed."
raise NotImplementedError(msg.format(subset=subset))
// -- FEATURE EXTRACTION --
// input sequence duration
duration = config["feature_extraction"]["duration"]
After Change
log_dir = workdir + "/" + dataset
// -- DATASET --
db, task, protocol, subset = dataset.split(".")
database = get_database(db, medium_template=medium_template)
protocol = database.get_protocol(task, protocol)
if not hasattr(protocol, subset):
raise NotImplementedError("")
file_generator = getattr(protocol, subset)()
// -- FEATURE EXTRACTION --
// input sequence duration
duration = config["feature_extraction"]["duration"]
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 24
Instances
Project Name: pyannote/pyannote-audio
Commit Name: 1522baaa3d0ced610ef1597ec8ef20d2fc0f29c0
Time: 2016-09-21
Author: bredin@limsi.fr
File Name: scripts/speaker_embedding.py
Class Name:
Method Name: train
Project Name: pyannote/pyannote-audio
Commit Name: 1522baaa3d0ced610ef1597ec8ef20d2fc0f29c0
Time: 2016-09-21
Author: bredin@limsi.fr
File Name: scripts/speaker_embedding.py
Class Name:
Method Name: train
Project Name: pyannote/pyannote-audio
Commit Name: 188fcda26afe3b53e78d49d3a5db2a69ce8c6ea6
Time: 2016-09-22
Author: bredin@limsi.fr
File Name: scripts/speech_activity_detection.py
Class Name:
Method Name: train
Project Name: pyannote/pyannote-audio
Commit Name: 1522baaa3d0ced610ef1597ec8ef20d2fc0f29c0
Time: 2016-09-21
Author: bredin@limsi.fr
File Name: scripts/speaker_embedding.py
Class Name:
Method Name: generate_test