logits_t = self.critic(states_t, actions_t)
// B x num_heads x num_atoms
logits_tp1 = self.target_critic(
states_tp1, self.target_actor(states_tp1)
).detach()
// B x num_heads x num_atoms
After Change
logits_t = self.critic(states_t, actions_t).squeeze_(dim=2)
// B x num_heads x num_atoms
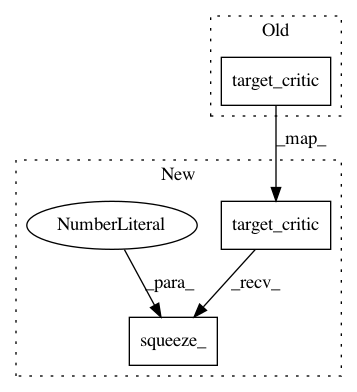
logits_tp1 = self.target_critic(
states_tp1, self.target_actor(states_tp1)
).squeeze_(dim=2).detach()
// B x num_heads x num_atoms
atoms_target_t = rewards_t + (1 - done_t) * gammas * self.z
// B x num_heads x num_atoms