b9968875e7bf05151900532270210e22daad45c2,cistar-dev/cistar/envs/lane_changing.py,SimpleLaneChangingAccelerationEnvironment,compute_reward,#SimpleLaneChangingAccelerationEnvironment#Any#Any#,52
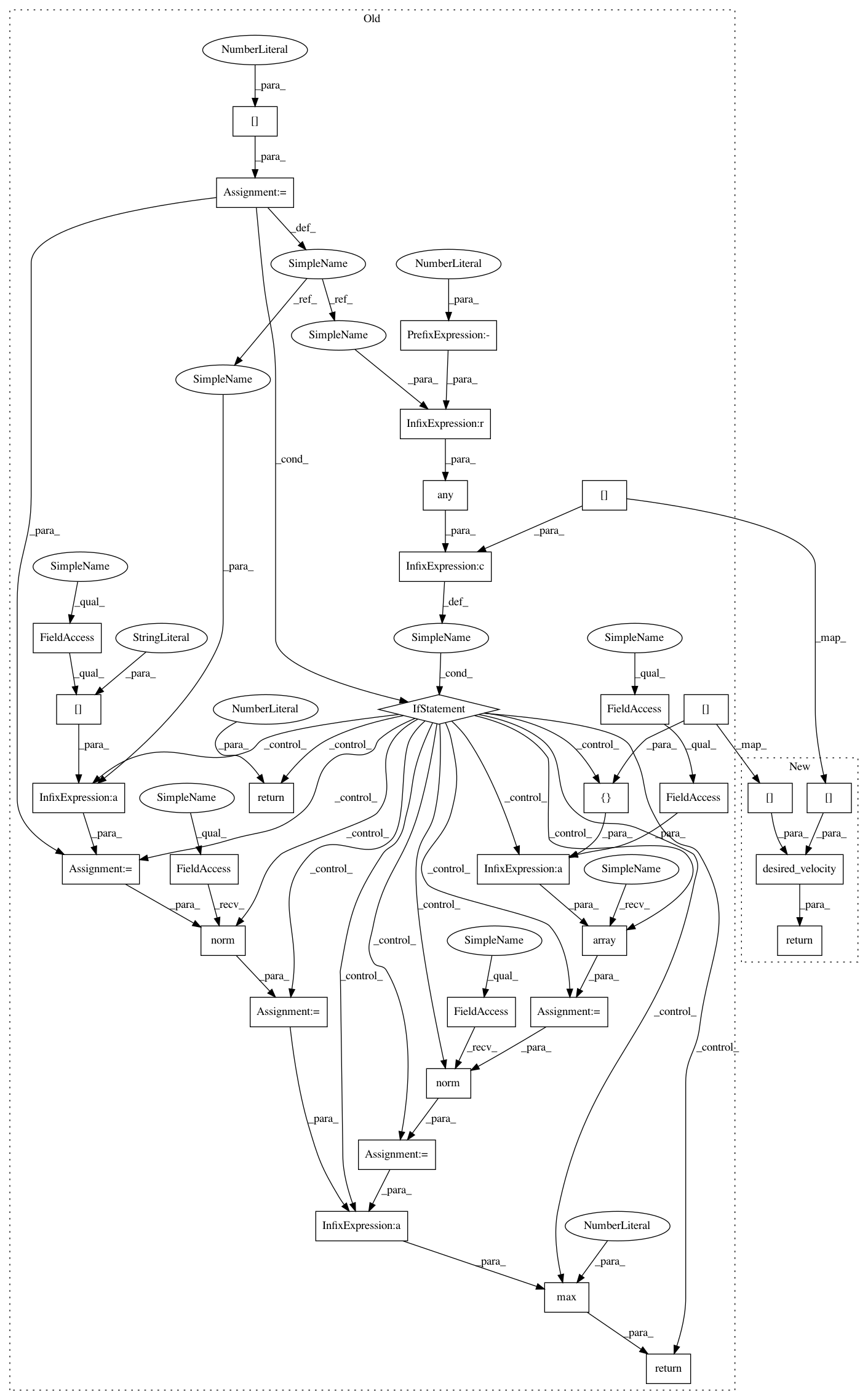
Before Change
See parent class
vel = state[0]
if any(vel < -100) or kwargs["fail"]:
return 0.0
max_cost = np.array([self.env_params["target_velocity"]]*self.scenario.num_vehicles)
max_cost = np.linalg.norm(max_cost)
cost = vel - self.env_params["target_velocity"]
cost = np.linalg.norm(cost)
return max(max_cost - cost, 0)
def getState(self, **kwargs):
See parent class
After Change
See parent class
return rewards.desired_velocity(
state, rl_actions, fail=kwargs["fail"], target_velocity=self.env_params["target_velocity"])
def getState(self):
See parent class
In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 33
Instances
Project Name: flow-project/flow
Commit Name: b9968875e7bf05151900532270210e22daad45c2
Time: 2017-07-10
Author: akreidieh@gmail.com
File Name: cistar-dev/cistar/envs/lane_changing.py
Class Name: SimpleLaneChangingAccelerationEnvironment
Method Name: compute_reward
Project Name: flow-project/flow
Commit Name: b9968875e7bf05151900532270210e22daad45c2
Time: 2017-07-10
Author: akreidieh@gmail.com
File Name: cistar-dev/cistar/envs/lane_changing.py
Class Name: SimpleLaneChangingAccelerationEnvironment
Method Name: compute_reward
Project Name: flow-project/flow
Commit Name: 6675ef7ddc08ab25eb6545943c7f4cc0234b62ee
Time: 2017-08-03
Author: akreidieh@gmail.com
File Name: cistar-dev/cistar/envs/braess_paradox.py
Class Name: BraessParadoxEnvironment
Method Name: compute_reward
Project Name: flow-project/flow
Commit Name: b9968875e7bf05151900532270210e22daad45c2
Time: 2017-07-10
Author: akreidieh@gmail.com
File Name: cistar-dev/cistar/envs/loop_accel.py
Class Name: SimpleAccelerationEnvironment
Method Name: compute_reward