checkpoint_restore_parts = args["--restore-parts"]
speaker_id = args["--speaker-id"]
speaker_id = int(speaker_id) if speaker_id is not None else None
preset = args["--preset"]
data_root = args["--data-root"]
if data_root is None:
data_root = join(dirname(__file__), "data", "ljspeech")
log_event_path = args["--log-event-path"]
reset_optimizer = args["--reset-optimizer"]
// Which model to be trained
train_seq2seq = args["--train-seq2seq-only"]
train_postnet = args["--train-postnet-only"]
// train both if not specified
if not train_seq2seq and not train_postnet:
print("Training whole model")
train_seq2seq, train_postnet = True, True
if train_seq2seq:
print("Training seq2seq model")
elif train_postnet:
print("Training postnet model")
else:
assert False, "must be specified wrong args"
// Load preset if specified
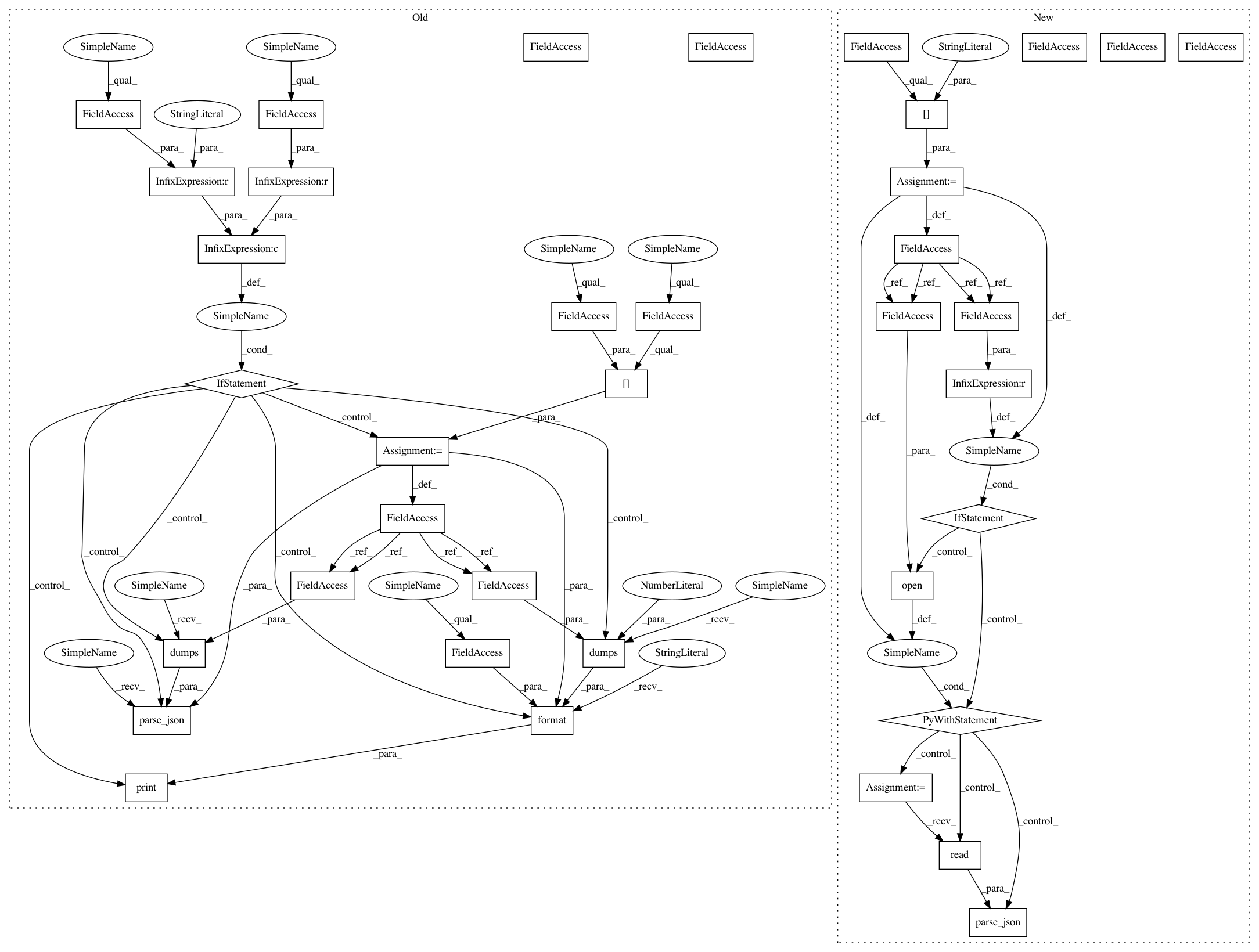
if preset is not None:
with open(preset) as f:
hparams.parse_json(f.read())
// Override hyper parameters
hparams.parse(args["--hparams"])
assert hparams.name == "deepvoice3"
print(hparams_debug_string())