52dd8f17b382dea2ddaf3b4054d7845c8c3b4f72,pycorrector/seq2seq/fce_reader.py,FCEReader,read_samples_by_string,#FCEReader#Any#,26
Before Change
def read_samples_by_string(self, path):
for tokens in self.read_tokens(path):
source = []
target = []
for token in tokens:
target.append(token)
if self.config.enable_data_dropout:
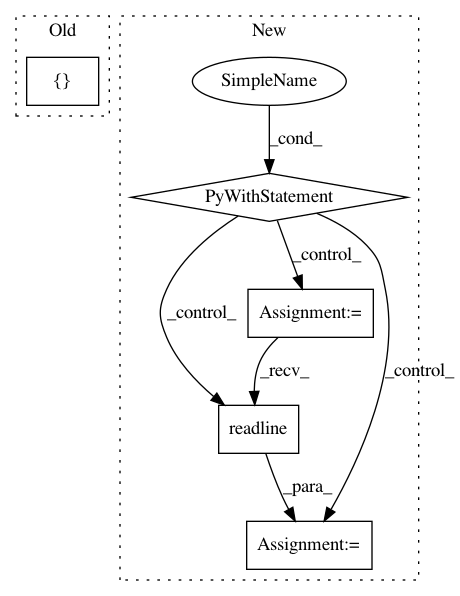
// Random dropout words from the inputAfter Change
self.UNKNOWN_ID = self.token_2_id[FCEReader.UNKNOWN_TOKEN]
def read_samples_by_string(self, path):
with open(path, "r", encoding="utf-8") as f:
line_src = f.readline()
line_dst = f.readline()
if line_src and line_dst:
source = line_src.lower()[5:].strip().split()
target = line_dst.lower()[5:].strip().split()
if self.config.enable_data_dropout:
new_source = []
for token in source:
// Random dropout words from the input
dropout_token = (token in FCEReader.DROPOUT_TOKENS and random.random() < self.dropout_prob)
replace_token = (token in FCEReader.REPLACEMENTS and random.random() < self.replacement_prob)
if replace_token:
new_source.append(FCEReader.REPLACEMENTS[source])
elif not dropout_token:
new_source.append(token)
source = new_source
yield source, target
def unknown_token(self):
return FCEReader.UNKNOWN_TOKEN
def read_tokens(self, path):In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 5
Instances Project Name: shibing624/pycorrector
Commit Name: 52dd8f17b382dea2ddaf3b4054d7845c8c3b4f72
Time: 2018-03-29
Author: 507153809@qq.com
File Name: pycorrector/seq2seq/fce_reader.py
Class Name: FCEReader
Method Name: read_samples_by_string
Project Name: deepchem/deepchem
Commit Name: 8a49ad8d672e3298c2a64384fb7268a8da7152c7
Time: 2017-12-06
Author: jth82@drexel.edu
File Name: deepchem/molnet/load_function/pcba_datasets.py
Class Name:
Method Name: load_pcba
Project Name: etal/cnvkit
Commit Name: 11b587a508198cd212321eb9e3c055a7466fbd07
Time: 2015-04-28
Author: eric.talevich@gmail.com
File Name: setup.py
Class Name:
Method Name: