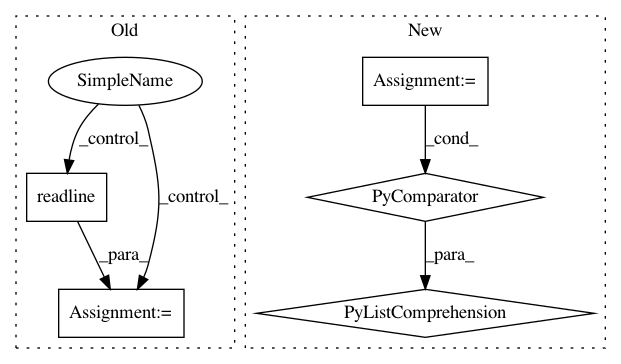
documents = []
with codecs.open(fnm, "rb", "ascii") as f:
line = f.readline()
while line != "":
documents.append(Text(json.loads(line)))
line = f.readline()
return documents
After Change
-------
list of Text
return [text for text in yield_json_corpus(fnm)]
def write_json_corpus(documents, fnm):
Write a lisst of Text instances as JSON corpus on disk.