if decoding_constraint and t-divm > 0:
logprobsf.scatter_(1, beam_seq_table[divm][t-divm-1].unsqueeze(1).cuda(), float("-inf"))
if remove_bad_endings and t-divm > 0:
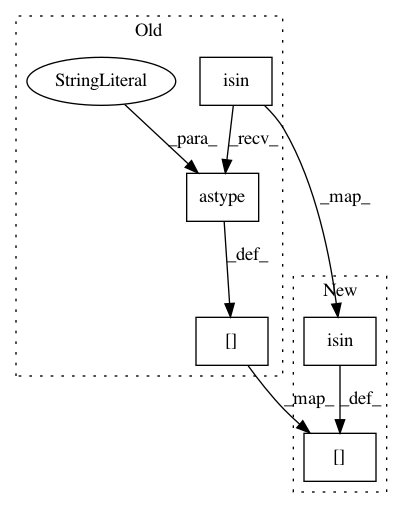
logprobsf[torch.from_numpy(np.isin(beam_seq_table[divm][t-divm-1].cpu().numpy(), self.bad_endings_ix).astype("uint8")), 0] = float("-inf")
// suppress UNK tokens in the decoding
if suppress_UNK and hasattr(self, "vocab") and self.vocab[str(logprobsf.size(1)-1)] == "UNK":
logprobsf[:,logprobsf.size(1)-1] = logprobsf[:, logprobsf.size(1)-1] - 1000
// diversity is added here
// the function directly modifies the logprobsf values and hence, we need to return
// the unaugmented ones for sorting the candidates in the end. // for historical
After Change
if decoding_constraint and t-divm > 0:
logprobsf.scatter_(1, beam_seq_table[divm][t-divm-1].unsqueeze(1).cuda(), float("-inf"))
if remove_bad_endings and t-divm > 0:
logprobsf[torch.from_numpy(np.isin(beam_seq_table[divm][t-divm-1].cpu().numpy(), self.bad_endings_ix)), 0] = float("-inf")
// suppress UNK tokens in the decoding
if suppress_UNK and hasattr(self, "vocab") and self.vocab[str(logprobsf.size(1)-1)] == "UNK":
logprobsf[:,logprobsf.size(1)-1] = logprobsf[:, logprobsf.size(1)-1] - 1000
// diversity is added here
// the function directly modifies the logprobsf values and hence, we need to return
// the unaugmented ones for sorting the candidates in the end. // for historical