if cardinality is None:
// If candidate_ranges is provided, use this to determine cardinality
if candidate_ranges is not None:
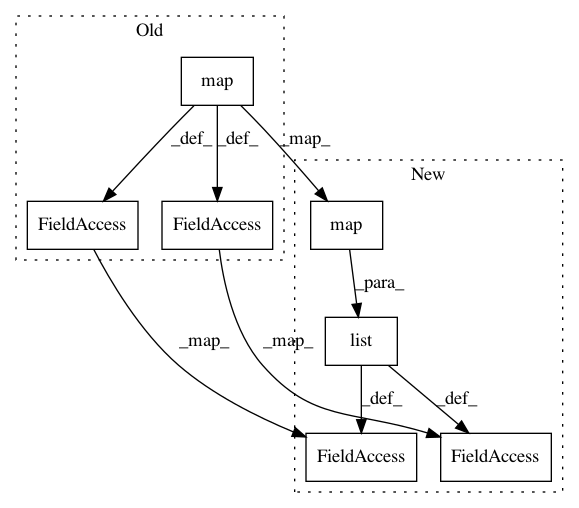
cardinality = max(map(max, candidate_ranges))
else:
// This is just an annoying hack for LIL sparse matrices...
try:
lmax = L.max()
except AttributeError:
lmax = L.tocoo().max()
if lmax > 2:
cardinality = lmax
elif lmax < 2:
cardinality = 2
else:
raise ValueError(
"L.max() == %s, cannot infer cardinality." % lmax)
print("Inferred cardinality: %s" % cardinality)
self.cardinality = cardinality
// Priors for LFs default to fixed prior value
// NOTE: Setting default != 0.5 creates a (fixed) factor which increases
// runtime (by ~0.5x that of a non-fixed factor)...
if LF_acc_prior_weights is None:
LF_acc_prior_weights = [LF_acc_prior_weight_default for _ in range(n)]
else:
LF_acc_prior_weights = list(copy(LF_acc_prior_weights))
// LF weights are un-fixed
is_fixed = [False for _ in range(n)]
// If supervised labels are provided, add them as a fixed LF with prior
// Note: For large L this column stack operation could be very
// inefficient, can consider refactoring...
if labels is not None:
labels = labels.reshape(m, 1)
L = sparse.hstack([L, labels])
is_fixed.append(True)
LF_acc_prior_weights.append(label_prior_weight)
n += 1
// Reduce overhead of tracking indices by converting L to a CSR sparse matrix.
L = sparse.csr_matrix(L).copy()
// If candidate_ranges is provided, remap the values of L using
// candidate_ranges. This "scoped categorical" approach allows learning
// and inference to be efficient even with very large cardinality, as
// we only sample relevant values for each candidate. Also set
// per-candidate cardinalities according to candidate_ranges if not None,
// else as constant value.
self.cardinalities = self.cardinality * np.ones(m, dtype=np.int64)
self.candidate_ranges = candidate_ranges
if self.candidate_ranges is not None:
L, self.cardinalities, _ = self._remap_scoped_categoricals(L,
self.candidate_ranges)
// Shuffle the data points, cardinalities, and candidate_ranges
idxs = range(m)
self.rng.shuffle(idxs)
L = L[idxs, :]
if candidate_ranges is not None:
self.cardinalities = self.cardinalities[idxs]
c_ranges_reshuffled = []
for i in idxs:
c_ranges_reshuffled.append(self.candidate_ranges[i])
self.candidate_ranges = c_ranges_reshuffled
// Compile factor graph
self._process_dependency_graph(L, deps)
weight, variable, factor, ftv, domain_mask, n_edges = self._compile(
L, init_deps, init_class_prior, LF_acc_prior_weights, is_fixed, self.cardinalities)
fg = NumbSkull(
n_inference_epoch=0,
n_learning_epoch=epochs,
stepsize=step_size,
decay=decay,
reg_param=reg_param,
regularization=reg_type,
truncation=truncation,
quiet=(not verbose),
verbose=verbose,
learn_non_evidence=True,
burn_in=burn_in,
nthreads=threads
)
fg.loadFactorGraph(weight, variable, factor, ftv, domain_mask, n_edges)
if timer is not None:
timer.start()
fg.learning(out=False)
if timer is not None:
timer.end()
self._process_learned_weights(L, fg, LF_acc_prior_weights, is_fixed)
// Store info from factor graph
if self.candidate_ranges is not None:
self.cardinality_for_stats = int(max(self.cardinalities))
else:
self.cardinality_for_stats = self.cardinality
self.learned_weights = fg.factorGraphs[0].weight_value
weight, variable, factor, ftv, domain_mask, n_edges =\
self._compile(sparse.coo_matrix((1, n), L.dtype), init_deps,
init_class_prior, LF_acc_prior_weights, is_fixed,
[self.cardinality_for_stats])
variable["isEvidence"] = False
weight["isFixed"] = True
weight["initialValue"] = fg.factorGraphs[0].weight_value
fg.factorGraphs = []
fg.loadFactorGraph(weight, variable, factor, ftv, domain_mask, n_edges)
self.fg = fg
self.nlf = n
self.cardinality = cardinality
def _remap_scoped_categoricals(self, L_in, candidate_ranges):
After Change
if cardinality is None:
// If candidate_ranges is provided, use this to determine cardinality
if candidate_ranges is not None:
cardinality = max(list(map(max, candidate_ranges)))
else:
// This is just an annoying hack for LIL sparse matrices...
try:
lmax = L.max()
except AttributeError:
lmax = L.tocoo().max()
if lmax > 2:
cardinality = lmax
elif lmax < 2:
cardinality = 2
else:
raise ValueError(
"L.max() == %s, cannot infer cardinality." % lmax)
print("Inferred cardinality: %s" % cardinality)
self.cardinality = cardinality
// Priors for LFs default to fixed prior value
// NOTE: Setting default != 0.5 creates a (fixed) factor which increases
// runtime (by ~0.5x that of a non-fixed factor)...
if LF_acc_prior_weights is None:
LF_acc_prior_weights = [LF_acc_prior_weight_default for _ in range(n)]
else:
LF_acc_prior_weights = list(copy(LF_acc_prior_weights))
// LF weights are un-fixed
is_fixed = [False for _ in range(n)]
// If supervised labels are provided, add them as a fixed LF with prior
// Note: For large L this column stack operation could be very
// inefficient, can consider refactoring...
if labels is not None:
labels = labels.reshape(m, 1)
L = sparse.hstack([L, labels])
is_fixed.append(True)
LF_acc_prior_weights.append(label_prior_weight)
n += 1
// Reduce overhead of tracking indices by converting L to a CSR sparse matrix.
L = sparse.csr_matrix(L).copy()
// If candidate_ranges is provided, remap the values of L using
// candidate_ranges. This "scoped categorical" approach allows learning
// and inference to be efficient even with very large cardinality, as
// we only sample relevant values for each candidate. Also set
// per-candidate cardinalities according to candidate_ranges if not None,
// else as constant value.
self.cardinalities = self.cardinality * np.ones(m, dtype=np.int64)
self.candidate_ranges = candidate_ranges
if self.candidate_ranges is not None:
L, self.cardinalities, _ = self._remap_scoped_categoricals(L,
self.candidate_ranges)
// Shuffle the data points, cardinalities, and candidate_ranges
idxs = list(range(m))
self.rng.shuffle(idxs)
L = L[idxs, :]
if candidate_ranges is not None:
self.cardinalities = self.cardinalities[idxs]
c_ranges_reshuffled = []
for i in idxs:
c_ranges_reshuffled.append(self.candidate_ranges[i])
self.candidate_ranges = c_ranges_reshuffled
// Compile factor graph
self._process_dependency_graph(L, deps)
weight, variable, factor, ftv, domain_mask, n_edges = self._compile(
L, init_deps, init_class_prior, LF_acc_prior_weights, is_fixed, self.cardinalities)
fg = NumbSkull(
n_inference_epoch=0,
n_learning_epoch=epochs,
stepsize=step_size,
decay=decay,
reg_param=reg_param,
regularization=reg_type,
truncation=truncation,
quiet=(not verbose),
verbose=verbose,
learn_non_evidence=True,
burn_in=burn_in,
nthreads=threads
)
fg.loadFactorGraph(weight, variable, factor, ftv, domain_mask, n_edges)
if timer is not None:
timer.start()
fg.learning(out=False)
if timer is not None:
timer.end()
self._process_learned_weights(L, fg, LF_acc_prior_weights, is_fixed)
// Store info from factor graph
if self.candidate_ranges is not None:
self.cardinality_for_stats = int(max(self.cardinalities))
else:
self.cardinality_for_stats = self.cardinality
self.learned_weights = fg.factorGraphs[0].weight_value
weight, variable, factor, ftv, domain_mask, n_edges =\
self._compile(sparse.coo_matrix((1, n), L.dtype), init_deps,
init_class_prior, LF_acc_prior_weights, is_fixed,
[self.cardinality_for_stats])
variable["isEvidence"] = False
weight["isFixed"] = True
weight["initialValue"] = fg.factorGraphs[0].weight_value
fg.factorGraphs = []
fg.loadFactorGraph(weight, variable, factor, ftv, domain_mask, n_edges)
self.fg = fg
self.nlf = n
self.cardinality = cardinality
def _remap_scoped_categoricals(self, L_in, candidate_ranges):