837b2efde71507b09033c3ea6f2502e2306f8eef,pymorphy2/analyzer.py,MorphAnalyzer,_parse_as_word_with_known_suffix,#MorphAnalyzer#Any#Any#,219
Before Change
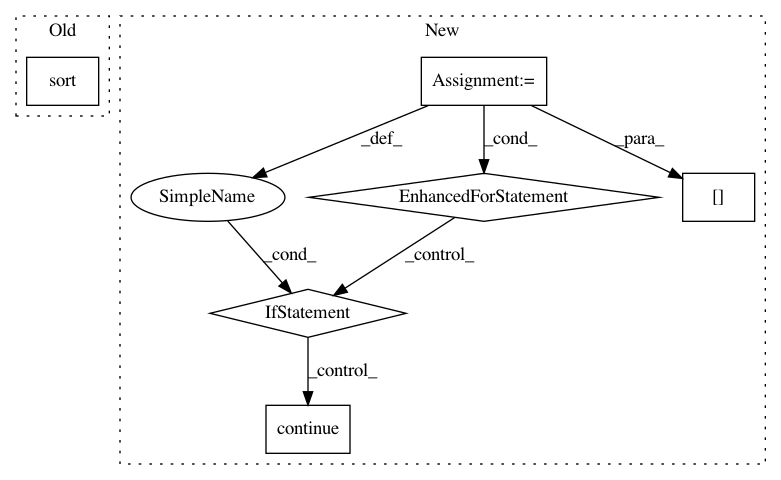
if total_cnt > 1:
// parses are sorted inside paradigms, but they are unsorted overall
result.sort(reverse=True)
result = [
(fixed_word, tag, normal_form, para_id, idx, cnt/total_cnt * ESTIMATE_DECAY)
for (cnt, fixed_word, tag, normal_form, para_id, idx) in result
]After Change
total_counts = [1] * len(self._paradigm_prefixes) // smoothing; XXX: isn"t max_cnt better?
for prefix_id, prefix in self._paradigm_prefixes:
if not word.startswith(prefix):
continue
suffixes_dawg = self._dictionary.prediction_suffixes_dawgs[prefix_id]
for i in self._prediction_splits:
end = word[-i:] // XXX: this should be counted once, not for each prefix
para_data = suffixes_dawg.similar_items(end, self._ee)
for fixed_suffix, parses in para_data:
for cnt, para_id, idx in parses:
tag = self._build_tag_info(para_id, idx)
if not tag.is_productive():
continue
total_counts[prefix_id] += cnt
fixed_word = word[:-i] + fixed_suffix
normal_form = self._build_normal_form(para_id, idx, fixed_word)
parse = (cnt, fixed_word, tag, normal_form, para_id, idx, prefix_id)
reduced_parse = parse[1:4]
if reduced_parse in _seen_parses:
continue
result.append(parse)
if total_counts[prefix_id] > 1:
break
result = [
(fixed_word, tag, normal_form, para_id, idx, cnt/total_counts[prefix_id] * ESTIMATE_DECAY)
for (cnt, fixed_word, tag, normal_form, para_id, idx, prefix_id) in result
]In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 6
Instances Project Name: kmike/pymorphy2
Commit Name: 837b2efde71507b09033c3ea6f2502e2306f8eef
Time: 2013-02-18
Author: kmike84@gmail.com
File Name: pymorphy2/analyzer.py
Class Name: MorphAnalyzer
Method Name: _parse_as_word_with_known_suffix
Project Name: jsalt18-sentence-repl/jiant
Commit Name: 9a4540b682074d3f84a2fc232cf2a832dc96bce7
Time: 2018-01-19
Author: wang.alex.c@gmail.com
File Name: src/aggregate_results.py
Class Name:
Method Name: latexify
Project Name: nipy/dipy
Commit Name: 1515fa64e1c94bca111980ed71b0423b891c5189
Time: 2015-11-13
Author: garyfallidis@gmail.com
File Name: dipy/reconst/dsi.py
Class Name:
Method Name: create_qtable