2c4a6e537126f4123de7c97f30587310d3712c06,allennlp/data/token_indexers/token_characters_indexer.py,TokenCharactersIndexer,token_to_indices,#TokenCharactersIndexer#Any#Any#,45
Before Change
for character in self._character_tokenizer.tokenize(token)[0]:
// If our character tokenizer is using byte encoding, the character might already be an
// int. In that case, we"ll bypass the vocabulary entirely.
if isinstance(character, int) :
index = character
else:
index = vocabulary.get_token_index(character, self._namespace)After Change
@overrides
def token_to_indices(self, token: Token, vocabulary: Vocabulary) -> List[int]:
indices = []
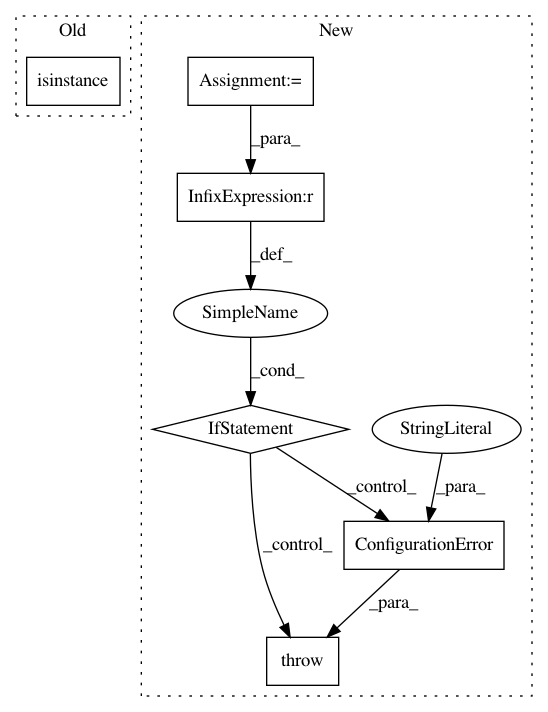
if token.text is None:
raise ConfigurationError("TokenCharactersIndexer needs a tokenizer that retains text")
for character in self._character_tokenizer.tokenize(token.text):
if getattr(character, "text_id", None) is not None:
// `text_id` being set on the token means that we aren"t using the vocab, we just
// use this id instead.In pattern: SUPERPATTERN
Frequency: 3
Non-data size: 6
Instances Project Name: allenai/allennlp
Commit Name: 2c4a6e537126f4123de7c97f30587310d3712c06
Time: 2017-09-13
Author: mattg@allenai.org
File Name: allennlp/data/token_indexers/token_characters_indexer.py
Class Name: TokenCharactersIndexer
Method Name: token_to_indices
Project Name: allenai/allennlp
Commit Name: 2c4a6e537126f4123de7c97f30587310d3712c06
Time: 2017-09-13
Author: mattg@allenai.org
File Name: allennlp/data/token_indexers/token_characters_indexer.py
Class Name: TokenCharactersIndexer
Method Name: count_vocab_items
Project Name: allenai/allennlp
Commit Name: e08ade81ff6684869883ce3da66941b9d3a37503
Time: 2019-01-15
Author: joelgrus@gmail.com
File Name: allennlp/commands/find_learning_rate.py
Class Name:
Method Name: find_learning_rate_model